Siguiente: Complementos y casos especiales Arriba: Sistemas de Detección de Intrusiones Previo: Definiciones
3.1.1 Fuentes de información basadas en máquina
3.1.1.1 Registros de auditoría
3.1.1.2 Contenido de los registros de auditoría
3.1.1.3 El problema de la reducción de auditoría
3.1.1.5 Registros de sistema comunes
3.1.1.6 Información de aplicaciones
3.1.1.7 Información recogida de objetivos
3.1.2 Fuentes de información basadas en red
3.1.2.4 Estructura de una dirección IP
3.1.2.8 Fuentes de información externas
3.1.3 Información de productos de seguridad
3.1.3.1 Otros componentes como fuentes de datos
3.2.1 Objetivos y elementos principales
3.2.1.2 Requisitos y objetivos secundarios
3.2.2.1 Construcción del analizador
3.2.2.2 Realización del análisis
3.2.2.3 Refinamiento y reestructuración
3.2.3.1 Detección de usos indebidos
3.2.3.2 Detección de anomalías
3.3.1 Primeras consideraciones
3.3.3 Observaciones sobre las respuestas
3.3.3.3 Almacenamiento de registros
3.3.4 Adopción de políticas de respuesta
Capítulo 3
Modelo de funcionamiento
En este capítulo se describe en detalle el modelo más aceptado para la detección de intrusiones. Tiene tres funciones principales, la fase de recogida de datos (fuentes de información), la fase de análisis, y la fase de respuesta. En líneas generales, para que la detección de intrusiones pueda obtener buenos resultados, debe llevar a cabo un proceso de recopilación de información, que posteriormente deberá someter a diversas técnicas de análisis, y en función de los datos obtenidos tendrá que dar algún tipo de respuesta.
3.1 Fuentes de información
Como se comentó en el capítulo anterior, la detección de intrusiones se puede clasificar según las fuentes de información que utiliza. Aquí se estudiaran los casos pertenecientes a la recopilación de datos basados en máquina, en red, y en fuentes externas como sistemas de seguridad físicos. Explicados en ese orden, se tratan las capas de menor a mayor nivel de abstracción.
Ninguno de los sistemas de detección de intrusiones en particular es mejor que los otros. La elección de una detección de intrusiones basada en máquina, red o cualquier otra, depende de las necesidades particulares. A veces basta con instalar un detector en algunos tramos de red, mientras que en otras ocasiones es necesario incrementar la seguridad recogiendo datos de las máquinas.
3.1.1 Fuentes de información basadas en máquina
Este tipo de fuentes de información consisten principalmente en registros de auditoría de sistemas operativos (registros generados por mecanismos del sistema operativo), y los registros de sistema (ficheros generados por el sistema y aplicaciones, generalmente ficheros de texto generados línea a línea). Los monitores basados en múltiples "hosts" utilizan las mismas fuentes, por lo que los apartados a continuación también son aplicables a estos.
3.1.1.1 Registros de auditoría
El primer elemento de importancia en sistemas de detección basados en máquina son los registros de auditoría. Estos registros son una colección de información sobre las actividades del sistema, creados cronológicamente y dispuestos en un conjunto de ficheros de auditoría. Estos registros son originados por los usuarios y los procesos y comandos que estos invocan. Muchos de los registros de auditoría fueron creados originalmente para cumplir los requisitos del Programa de Evaluación de Productos Fiables (TCSEC), una iniciativa del gobierno estadounidense. El TCSEC, también conocido como Libro Naranja, define las características requeridas por los sistemas operativos de uso comercial y las aplicaciones de software que contuvieran o procesaran información clasificada. [1]
Por aquel entonces, el Libro Naranja presentaba un problema, ya que presentaba extensos requerimientos de auditoría, pero no las directrices para su utilización. Listaba una gran cantidad sucesos que debían ser registrados, pero posteriormente no explicaba la forma de seleccionarlos. Tampoco explicaba de qué modo o con qué estructura debían ser almacenados los registros de auditoría. Por lo tanto, los fabricantes crearon numerosas y variadas soluciones para cumplir los requerimientos de auditoría de la clase C2(1). Los desarrolladores de detección de intrusiones que se familiarizaban con los registros de auditoría de un sistema operativo no comprendían los registros generados por otro sistema, que podía estar cumpliendo los mismos requerimientos.
Los fabricantes utilizaron al menos dos soluciones en sus sistemas de auditoría. Una creaba registros "autónomos", que no necesitaban de otros registros para su interpretación. La eliminaba información redundante en los registros almacenando la información de un evento en registros múltiples.
Los sistemas de detección de intrusiones hacen un uso importante de la información contenida en los registros de auditoría. Desgraciadamente, gran parte de los sistemas operativos comerciales existentes no cumplen con los requisitos de auditoría necesarios, a pesar de la documentación que hay sobre el tema. Esto dificulta la labor a los desarrolladores de detección de intrusiones. Algunos han sugerido que para una detección de intrusiones basada en máquina sea efectiva es necesario añadir funcionalidades al núcleo del sistema para que genere la información de auditoría necesaria. Esto provoca costes en el rendimiento del sistema, y costes asociados al mantenimiento de las alteraciones de los sistemas operativos. [2]
No obstante, muchos desarrolladores prefieren utilizar los registros de auditoría frente otras fuentes de información por varias razones. Una de ellas es que la propia estructura del sistema operativo está diseñada para otorgar suficiente seguridad al sistema de auditoría, y los registros que este genera. Otro de los motivos que les llevan a esta decisión es que el sistema de auditoría trabaja a bajo nivel, por lo que ofrece mayor nivel de detalle que el que puede ofrecer otro mecanismo.
Sin embargo, es importante resaltar que obtener datos excesivamente detallados dificulta la diferenciación entre las actividades originadas directamente por usuarios y aquellas originadas por programas que han tomado la identidad de un usuario. Hay numerosos ataques que explotan la capacidad de los programas para asumir la identidad de un usuario que tiene mayores privilegios que el actual. Para detectar esta clase de ataques, la fuente de datos debe proporcionar suficiente información para permitir la diferenciación entre usuario y proceso.
3.1.1.2 Contenido de los registros de auditoría
Los eventos de sistema contienen información sobre la actividad del sistema como del objeto que la ha originado. Los sistemas operativos comerciales guardan eventos a nivel de núcleo (llamadas de sistema) y a nivel de usuario (eventos de aplicación). Para identificar a los procesos y a los usuarios, se proporciona información inequívoca sobre los procesos e identificadores de usuario (userID). A veces incluso se registra el userID original, y el userID adoptado por el proceso, si este ha cambiado.
A continuación se explicará la estructura del sistema de auditoría de dos sistemas operativos: Sun, el Basic Security Module (BSM) y Windows NT.
3.1.1.2.1 Solaris BSM
El Módulo de Seguridad Básico de Sun se ha diseñado para cumplir los requisitos del TCSEC C2.
La estructura del subsistema de auditoría de BSM consiste en un registro ("log") de auditoría, varios ficheros de auditoría, informes ("records") de auditoría, y testigos ("tokens") de auditoría.
Un registro de auditoría consiste en un conjunto de ficheros de auditoría, que a su vez están compuestos por varios informes de auditoría. Estos informes, como se verá más adelante, están formados por varios testigos de auditoría.
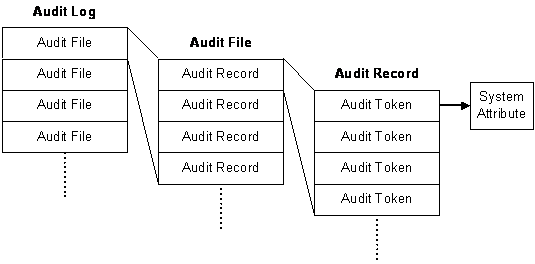
Figura 3‑1 - Estructura de los registros de auditoría BSM
Cada informe de auditoría se almacena en formato binario y describe cada evento ocurrido, e incluye información tal como quién hizo la acción, qué ficheros están involucrados, qué acción tuvo lugar y dónde y cómo sucedió. [3]
La Figura 3‑2 muestra el conjunto de testigos que constituyen un informe de auditoría.
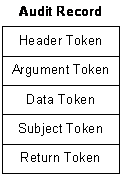
Figura 3‑2 - Estructura de un informe ("record") de auditoría BSM
Hay eventos generados a nivel de núcleo ("kernel-level audit events") y a nivel de usuario ("user-level audit events"). La estructura de ambos es similar.
Para facilitar la labor de la auditoría, los eventos están organizados por clases ("audit classes"). Existen 32 clases de auditoría.
Para configurar la auditoría se utilizan indicadores de auditoría ("audit flags"), que permiten especificar qué clases eventos auditar.
El sistema operativo ofrece algunas herramientas para la gestión de los eventos de auditoría. De esta manera, se puede utilizar el comando praudit para traducir los historiales de auditoría almacenados en binario en un formato legible para el usuario. Por otra parte, auditreduce permite realizar filtrados de los eventos generados, a partir de parámetros como intervalos de tiempo, determinados identificadores de usuarios, o determinados eventos de sistema.
3.1.1.2.2 Windows NT/2000
Este sistema operativo genera tres tipos de eventos de sistema:
· Eventos de sistema operativo.
· Eventos de seguridad.
· Eventos de aplicación.
Los eventos de sistema son los que generan los componentes de Windows. Son sucesos relacionados con fallos de controladores u otros objetos de sistema, pérdida de datos, problemas con el registro, etc. Estos tipos de eventos son predeterminados por el sistema operativo.
Los eventos de aplicación son los generados por las diferentes aplicaciones del sistema. Por ejemplo, información asociada a una base de datos, un antivirus, o una operación de copia de seguridad. Estos eventos los definen los desarrolladores de software, y los "software toolkits" (conjuntos de herramientas "software") les ayudan en esta labor.
Los eventos de seguridad son los que tienen especial relevancia en materia de seguridad. Están diseñados a partir de las definiciones del TCSEC (clase C2). Estos eventos tienen que ver con accesos a objetos, inicios y cierres de sesión, cambio de políticas de sistema, etc. A diferencia de los otros tipos de sucesos, estos sólo pueden ser accedidos por administradores, y son los más importantes para los detectores de intrusiones.
Los registros de eventos de Windows están formados por historiales de eventos. Cada historial tiene una cabecera, seguida de una descripción y, a veces, datos adicionales. La cabecera tiene los siguientes campos. La mayoría son auto explicativos: Fecha, Hora, Nombre de Usuario, nombre de Máquina, ID de evento, Fuente (una aplicación, un servicio de sistema, un controlador), Tipo (indica la gravedad del evento: un error, un aviso, una información, éxito, fracaso), Categoría (utilizado principalmente en eventos de seguridad para indicar qué evento ha tenido éxito o fracaso).
Al igual que pasa con el sistema operativo Solaris de Sun, Windows NT proporciona varios elementos para hacer más llevadera la auditoría. Existen mecanismos de filtrado de sucesos. También es posible ordenarlos, ascendente o descendentemente, según los distintos elementos que componen cada evento. Se pueden definir parámetros tales como el tamaño del archivo del registro de eventos, y cómo se debe comportar el sistema en caso de llenarse, pudiéndose detenerse inmediatamente o sobrescribir los más antiguos.
|
Permission Components (Windows NT and Windows 2000) |
Permission Types (Windows NT) | |||||
|
Read (R) |
Write (W) |
Execute (X) |
Delete (D) |
Change Permissions (P) |
Take Ownership (O) | |
|
Traverse Folder / |
|
|
• |
|
|
|
|
List Folder / |
• |
|
|
|
|
|
|
Read Attributes |
• |
|
• |
|
|
|
|
Read Extended Attributes |
• |
|
|
|
|
|
|
Create Files / |
|
• |
|
|
|
|
|
Create Folders / |
|
• |
|
|
|
|
|
Write Attributes |
|
• |
|
|
|
|
|
Write Extended Attributes |
|
• |
|
|
|
|
|
Delete Subfolders and Files |
|
|
|
|
|
|
|
Delete |
|
|
|
• |
|
|
|
Read Permissions |
• |
• |
• |
|
|
|
|
Change Permissions |
|
|
|
|
• |
|
|
Take Ownership |
|
|
|
|
|
• |
Tabla 3‑1 - Permisos en Windows NT y Windows 2000
La Tabla 3‑1 muestra la relación entre los permisos básicos de Windows NT (lectura, escritura, ejecución, etc.) y los distintos componentes de permisos, indicados a la izquierda, formados a partir de combinaciones de aquellos.
Establecer una política de auditoría eficaz no es trivial. Aunque se podrían auditar todos los elementos del sistema, rara vez es la solución adecuada. Por una parte, tal medida tendría un importante impacto en el rendimiento del sistema. Además, de esta forma se generan muchos más eventos, que en muchos casos son irrelevantes o inútiles, enturbiando la claridad de los datos y sobrecargando la fase de análisis.
3.1.1.3 El problema de la reducción de auditoría
La reducción de auditoría, en anglosajón "audit reduction", tiene lugar cuando se pretende eliminar información redundante o no necesaria de los registros de auditoría.
Un dato clave para llevar a cabo la reducción de auditoría es el de introducir determinismo en procesos relativamente no deterministas. Es decir, si sabemos que un suceso A siempre suele venir seguido de otros elementos dados (U, V, W) bajo ciertas condiciones (R, S), podemos determinar el suceso: A ocurre bajo condiciones R, S seguido de U, V, W, al suceso A.
Desgraciadamente, el determinismo no siempre es aplicable. Especialmente en entornos multitarea. Por ejemplo, en UNIX de Sun, un simple comando de alto nivel, como ls, en una estación de trabajo puede generar más de mil historiales de auditoría. Si este comando se repite en unos segundos puede generar un número distinto de eventos, y en diferente orden.
Existen todo tipo de mecanismos para llevar a cabo reducciones de auditoría. Desde simples filtrados de eventos según la información de alguno de sus campos. Hasta elaborados modelos matemáticos, como el "Filtro Basado en Concordancia de Patrones" [4] o la "Detección de Intrusiones utilizando patrones de rastro de auditoría de longitud variable" [5].
También hay importantes reducciones de eventos eliminando los eventos generados por procesos fiables. Aquí, los procesos fiables son aquellos certificados como soporte para obtener seguridad.
3.1.1.4 Registro de Sistema
El registro de sistema ("system log") es otro elemento importante a la hora de recopilar información del sistema. Es un fichero en el que se guardan los eventos generados por el sistema. El sistema operativo UNIX cuenta con una variedad importante de registros de sistema, relacionados por un servicio común, denominado "syslog". Este servicio genera y actualiza los registros de eventos mediante el proceso syslogd.
La seguridad de los registros de sistema es uno de los puntos débiles frente a la de los de auditoría. En este sentido, los registros de sistema son menos fiables que los de auditoría. Hay varias razones por las que esto es así. Los registros de sistema son escritos por aplicaciones, más vulnerables que el subsistema de auditoría. Por otra parte, suelen almacenarse en directorios no protegidos del sistema, relativamente fáciles de localizar y alterar. Además, están escritos en texto en claro, y no en una forma más críptica como los registros de auditoría, que siempre ayuda más a detectar cambios.
No obstante, los registros de sistema aportan información muy útil a los programas de detección de intrusiones, y complementan a los datos provenientes de los registros de auditoría. Además, son más fáciles de revisar que los registros de auditoría de sistema.
Por otra parte, siempre es más conveniente utilizar varias fuentes de información que una sola. Así, se pueden detectar signos de intrusiones a través de las discrepancias encontradas.
Para solventar los problemas de seguridad inherentes a los registros de sistema se han desarrollado diferentes métodos. Spafford y Garfinkel propusieron uno que consistía en enviar los registros de un sistema a una máquina dedicada utilizando una conexión serie [6].
3.1.1.5 Registros de sistema comunes
Como ya se explicó, existen numerosos registros de sistema. Pero no todos sirven para detectar intrusos. Los programas de recopilación de información de seguridad seleccionan los más relevantes. Los sistemas operativos basados en UNIX los almacenan en los directorios:
/usr/adm Utilizado en las primeras versiones de UNIX.
/var/adm Utilizado en versiones más modernas de UNIX.
/var/log Utilizado en algunas versiones de Linux, BSD, FreeBSD.
A continuación se muestra una tabla con los registros más utilizados por los sistemas de detección de intrusiones. Además de estos registros, los desarrolladores pueden utilizar syslogd para escribir eventos, ampliando las posibilidades de detección de intrusiones a procesos de sistema no predeterminados:
|
Nombre de registro |
Descripción |
|
acct or pacct |
Comandos ejecutados por todos los usuarios. |
|
aculog |
Llamadas de los módems. |
|
lastlog |
Última entrada con éxito y sin éxito en el sistema de cada usuario. |
|
loginlog |
Todos los intentos de acceso sin éxito. |
|
messages |
Mensajes de salida de la consola del sistema y otros generados desde el servicio syslog. |
|
sulog |
Uso del comando "su" |
|
utmp[x] |
Dentro de este o estos directorios está la información del usuario que está en el sistema. |
|
utmpx |
utmp extendido. |
|
wtmp[x] |
Contiene un listado de tiempos de cada entrada y salida de cada usuario. |
|
wtmpx |
wtmp extendido. |
|
xferlog |
Accessos mediante FTP. |
Tabla 3‑2 - Registros relativos a seguridad en Solaris
3.1.1.6 Información de aplicaciones
Hasta ahora nos hemos centrado en el nivel de sistema como fuente de información para la detección de intrusiones. El nivel de sistema se supone el más robusto e inaccesible para todos salvo los más expertos. Sin embargo, los modelos de seguridad y de protección están en constante evolución, al mismo tiempo que los sistemas operativos.
Los profesionales del campo de la detección de intrusiones piensan que en el futuro, la mayoría de los datos de importancia procederán del nivel de aplicación. Uno de los ejemplos de esta realidad es el progresivo avance de los sistemas distribuidos y los sistemas orientados a objetos. En el sistema operativo Windows NT, muchos de los eventos generados por el nivel de registro de sistema operativo han migrado a almacenes de datos de aplicación. Además, casi todos los sistemas operativos comerciales soportan la entrada de registros de auditoría generados en el nivel de aplicación.
3.1.1.6.1 Bases de datos
En las grandes organizaciones, cada vez con más frecuencia, la información se almacena y manipula mediante un sistema de gestión de bases de datos.
Uno de los aspectos más importantes de las bases de datos está relacionado con el volumen de información de auditoría que pueden generar. En algunos casos, se pueden producir "gigabytes" de datos de auditoría en cuestión de horas. Esto obliga, durante el diseño de sistemas de detección de intrusiones, a crear mecanismos de compresión para los datos, técnicas de reducción de auditoría, selección de grupos de eventos útiles descartando los no necesarios.
Los registros de las transacciones generadas por las bases de datos, al igual que los registros de sistema, no están tan protegidos como los eventos de auditoría. Pero ocurre que en las bases de datos se almacena información que los usuarios y las empresas desean proteger. Se están haciendo esfuerzos de desarrollo en este aspecto. Los sistemas de auditoría relacionados con la gestión de bases de datos son una fuente de información importante para los sistemas de detección de intrusiones. [7]
3.1.1.6.2 Servidores Web
Debido al enorme crecimiento experimentado en los últimos años del uso de estos servicios, los servidores Web son cada vez más utilizados. Muchos de estos servidores permiten la generación de valiosa información a nivel de aplicación, en forma de registros.
Aquí comentaré los formatos de los registros más estandarizados entre este tipo de aplicaciones.
Common Log Format (CLF)
Este formato fue utilizado originalmente por el servidor Web del NCSA (2), llegando a convertirse en el estándar a utilizar por los servidores Web en sus registros. La mayoría de las herramientas de análisis de registros lo soportan. Los registros CLF contienen casi toda la información necesaria para realizar estudios exhaustivos sobre la actividad de un servidor Web, cuya estructura se describe a continuación [8]:
|
Campo |
Descripción |
Ejemplos |
|
máquina remota |
Dirección IP o nombre DNS del cliente. |
192.168.0.1, www.upm.es |
|
rfc931 |
Identificación remota del cliente. No se aplica. "identd" es un servicio exclusivo de UNIX. La búsqueda de identidad consume mucho ancho de banda, y sobrecarga innecesariamente a los servidores. Raramente se utiliza. Si no existe se escribe un guión ("-"). |
|
|
Autenticación de usuario |
Nombre de usuario del cliente. |
diego, dggomez |
|
Fecha y hora |
Fecha y hora: formato |
[15/06/2003:23:23:00 +0100] |
|
Petición |
Línea de petición hecha por el cliente, entre comillas. |
"GET /menu.html HTTP/1.0" |
|
Estado [9] |
NNN. Estado HTTP devuelto al cliente, "-" si no está disponible. |
200, 406, 303 |
|
longitud |
NNNNN. Número de bytes enviados al cliente, "-" si no está disponible. |
1995, 573, 907, 2003 |
Tabla 3‑3 - Estructura de registros CLF
Un ejemplo válido de una entrada de registro CLF podría ser:
www.microsoft.com - - dggomez [10/07/2003:13:47:00 +0100] "GET /passw.txt HTTP/1.1" 200 1976
W3C Extended Log Format (ELF)
Consiste básicamente en el NSCA CLF más los campos agente de usuario ("user-agent") y URL de procedencia ("referrer URL information") sin comillas [10]. Quedando una estructura como la siguiente:
CLF user_agent referrer_URL
El siguiente registro, aunque en más de una línea por falta de espacio, podría ser un ejemplo válido de este formato:
www.euitt.upm.es - - dggomez [19/Mar/2003:21:14:55 -0200] "GET / HTTP/1.1" 200 1234 Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0) http://www.euitt.upm.es/index.html
Definable Lof Format (DLF)
Este formato muy similar al ELF, pero al final de cada entrada de registro invierte los campos URL de procedencia y agente de usuario, dejándolos con o sin comillas, de la siguiente forma:
CLF "referrer_URL" "user_agent"
CLF referrer_URL user_agent
Un ejemplo de este formato, sería similar a:
138.100.52.100 - - dggomez [08/Apr/2003:16:02:20 +0100] "GET / HTTP/1.1" 200 5678 "http://www.euitt.upm.es/index.html" "Mozilla/4.05 (X11; I; IRIX64 6.4 IP30)"
Existen más formatos, como el "Binary Log Format" (BLF), muy similar al NCSA CLF pero más sintetizado, con menos campos.
La obtención de datos de aplicaciones presenta dos de los grandes retos de la detección de intrusiones a la hora de recoger información. Por un lado está el problema del tiempo. Es fundamental establecer un orden cronológico o incluir algún parámetro de tiempo en las entradas de los registros para que la información pueda ser analizada correctamente. Por otra parte tenemos el problema de la combinación de los diferentes registros, para que los usuarios puedan comprenderlos adecuadamente. El proceso de combinar varios flujos de datos para obtener otra cosa se denomina composición (posible mediante correlación previa). Cuando estos flujos sirven para crear otro de nivel de abstracción más alto, se utiliza el término de inteligencia artificial fusión. Estos dos términos son dos aspectos técnicos muy relevantes en la detección de intrusiones.
Un ejemplo de producto de detección de intrusiones basado en aplicación es Appshield, de la empresa Sanctum Inc. [11]
3.1.1.7 Información recogida de objetivos
Un monitor basado en objetivo ("target based") es muy similar a un monitor basado en máquina ("host based"). La monitorización basada en objetivo establece mecanismos para vigilar el estado de una serie de recursos valiosos del sistema, grabando periódicamente el estado de los objetos monitorizados. Estos estados se comparan con unas políticas de seguridad, registrando las posibles discrepancias.
Uno de los recursos más utilizados para la monitorización basada en objetivo es el de los verificadores de integridad. Estas herramientas se utilizan para complementar la labor de los detectores de intrusiones, monitorizando cambios en el estado de objetos de sistema, como ficheros importantes. Este enfoque es estático, no como los mecanismos de registro de auditoría o sistema, que son dinámicos. Para aclarar el concepto, se podría decir que un ejemplo estático, como la monitorización basada en objetivo, es una imagen, mientras que uno dinámico es como un vídeo. Una cámara fotográfica puede hacer imágenes a intervalos periódicos de tiempo, mientras que una cámara de vídeo, que es más cara, permite ver lo que pasa en tiempo real. Cada solución depende de las necesidades particulares. Algunas empresas no necesitan una alta velocidad de detección.
Un verificador de integridad genera una suma de comprobación ("checksum") de cada objeto de sistema y las almacena en un lugar protegido. Para fabricar la suma de comprobación se utiliza un algoritmo de resumen de mensaje ("message digest algorithm"), o función de resumen ("hash funtion"). Estos algoritmos se diseñan con dos propósitos. Primero, para que sean tan seguros que el hecho de obtener el mismo resultado utilizando dos entradas distintas sea prácticamente nulo. Y segundo, para que cualquier modificación en la entrada, por pequeña que sea, produzca una enorme diferencia en la salida.
Los monitores basados en objetivos son especialmente útiles en sistemas UNIX. La razón es que en estos sistemas operativos, cualquier objeto de interés (como conexiones de red, procesos o dispositivos) puede ser representado como un fichero. Estos objetos se representan por estructuras denominadas inodos ("inodes").
|
Campo |
Bytes |
Descripción |
|
Mode |
2 |
Tipo de fichero, bits de protección, "setuid", bits "setgid" |
|
NLinks |
2 |
Número de entradas de directorio apuntando a este inodo |
|
Uid |
2 |
UID del propietario del fichero |
|
Gid |
2 |
GID del propietario del fichero |
|
Tamaño |
4 |
Tamaño del fichero en "bytes" |
|
Dirección |
39 |
Dirección de los primero 10 bloques de disco, luego 3 bloques indirectos |
|
Gen |
1 |
Número de generación (Se incrementa con cada reutilización del inodo) |
|
Atime |
4 |
Hora en la que el inodo fue accedido por última vez |
|
Mtime |
4 |
Hora en la que el inodo fue modificado por última vez |
|
Ctime |
4 |
Hora en la que el inodo fue cambiado por última vez |
Tabla 3‑4 - Contenido de un inodo del sistema de ficheros UNIX (System V)
Los primeros verificadores existentes en UNIX comprobaban el estado de los ficheros utilizando códigos de redundancia cíclica (CRC). Estos códigos fueron diseñados originalmente para detectar errores en comunicaciones sobre canales con ruido. Por lo tanto, detectaban cambios aleatorios en los objetivos y no cambios intencionados en sus contenidos. Algunos ataques demostraron que, con la ayuda de las herramientas adecuadas, era posible modificar el contenido de los ficheros sin alterar su CRC.
A principios de los años noventa, Gene Spafford y Gene Kim desarrollaron una herramienta denominada Tripwire® que optimizaba el proceso de crear códigos de resumen criptográfico para proteger ficheros críticos de sistema. Actualmente este programa es comercial, y está disponible para plataformas Solaris, Windows NT y Linux. [12]
3.1.2 Fuentes de información basadas en red
Los monitores basados en red son quizás los más famosos en el ámbito de la detección de intrusiones. El tráfico de red; flujo de información tal como viaja por un segmento de red, es la fuente de información que se tratará en esta sección.
La recopilación de datos de red tiene varias ventajas. Para empezar, utilizar como fuente de información el tráfico de red, no afecta al rendimiento del resto de las máquinas de la red.
Por otra parte, el monitor puede ser transparente al resto de los miembros de la red. Esto significa que puede ser indetectable, lo que es una ventaja ya que no puede convertirse en objetivo directo de posibles intrusos. Con este propósito, existe la posibilidad de utilizar un cable de sólo recepción ("sniffing cable") para el monitor, de forma que sólo pueda recibir datos, impidiendo físicamente cualquier envío de señales [13]. Una opción equivalente al cable de sólo recepción es el uso de un "network tap" (dispositivo de escucha de red); un dispositivo de aspecto similar a un concentrador de red, que permite a un rastreador pinchar las comunicaciones sin ser detectado.
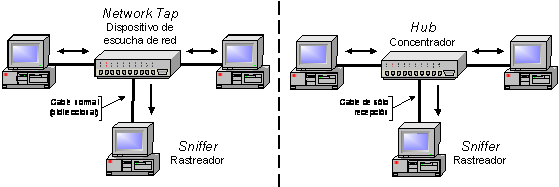
Figura 3‑3 - Dispositivo de escucha de red y cable de sólo recepción
Por último, el tráfico de red puede revelar información sobre ataques que no podrían ser detectables por un monitor basado en máquina. Estos ataques podrían ser basados en paquetes malformados y algunos de denegación de servicio.
3.1.2.1 Paquetes de red
Para extraer los paquetes de un segmento de red, un detector de intrusiones basado en red, suele utilizar un dispositivo de red en modo promiscuo. Esto hace que el dispositivo de red genere una interrupción cada vez que detecta algún paquete en la red. Una máquina dedicada a monitorizar tráfico de red de esta manera, se suele denominar "sniffer" (rastreador). Esté método es eficaz, pero tiene inconvenientes. Es útil en los casos en los que el dispositivo está situado en algún punto de la red en el que puede haber tráfico no destinado a sí mismo. Por ejemplo, en redes con "switches" (conmutadores), el modo promiscuo no es efectivo, ya que el dispositivo de red sólo recibe el tráfico destinado a él. Por otra parte, un rastreador tampoco puede monitorizar conexiones hechas con un módem, puesto que utilizan distintas interfaces.
En la Figura 3‑4 se observa a la izquierda un escenario con concentrador ("hub"), en el que el rastreador puede recibir todo el tráfico relacionado con las máquinas que comparten el medio. En la siguiente situación (con conmutador), el rastreador sólo detecta el tráfico enviado o destinado a él mismo. Por último, se ilustra un tipo de conexión que el rastreador no es capaz de interceptar.
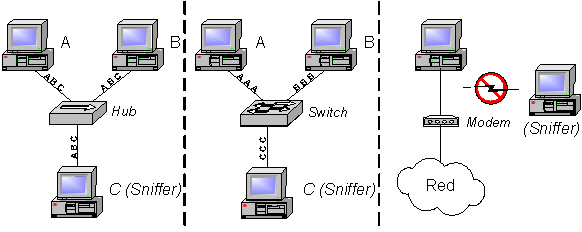
Figura 3‑4 - Escenarios de conexión de un rastreador
3.1.2.2 Redes TCP/IP
Los protocolos TCP ("Transmission Control Protocol") e IP ("Internet Protocol") son los más ampliamente utilizados en Internet. Estudiar cómo funcionan y cómo se estructuran sus datos es imprescindible para comprender y evitar los problemas de seguridad relacionados con el tráfico de red.
En 1977 se empezó a utilizar TCP, desarrollado en 1974 por Kahn y Cerf, para sustituir al NCP ("Network Control Protocol") en ARPAnet. TCP era más rápido, fácil de usar y de implementar que su predecesor. En 1978, IP se añadió al TCP, encargándose del encaminamiento de los mensajes. Varios años más tarde, en 1983, cualquier elemento conectado a ARPAnet debía soportar los protocolos TCP/IP. Fue entonces cuando se empezó a referirse a ARPAnet y sus redes como "Internet". [14]
Las redes TCP/IP son de conmutación de paquetes. Cuando se establece una comunicación entre dos elementos de red, se produce un intercambio de un número determinado de paquetes entre ellos. Estos paquetes pueden viajar a través de una serie de segmentos de red, interconectados por dispositivos como puertas de enlace ("gateways") y "routers", que los encaminan hacia su destino.
3.1.2.3 Pila de protocolos
La suite de protocolos TCP/IP está compuesta por cuatro niveles o capas, de forma que cada uno utiliza los servicios del nivel inferior. Para comprender su mejor su estructura, la expondremos frente al modelo propuesto por OSI ("Open Systems Interconnection").
OSI es la estructura de protocolos en siete niveles propuesta por ISO e ITU-T ("International Telecommunication Union Telecommunication Standardization Sector"). Este modelo es teóricamente más elaborado y didáctico que TCP/IP, por el contrario, más sencillo y práctico. Desgraciadamente, aunque OSI tiene muchos puntos a su favor, no ha logrado sustituir a la arquitectura TCP/IP como estándar en Internet. La figura siguiente muestra una comparación entre ambas pilas de protocolos. [15]
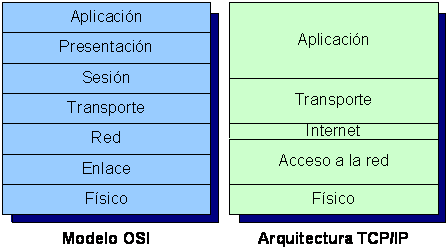
Figura 3‑5 - Modelo OSI y Arquitectura TCP/IP
3.1.2.4 Estructura de una dirección IP
Las direcciones del Protocolo Internet en su versión 4 están compuestas por un número de 32 bits. Cada dirección está dividida en dos partes, el identificador de red y el identificador de máquina. El identificador de máquina se suele utilizar para designar diferentes subredes ("subnetting"), aprovechando mejor el espacio de direcciones y optimizando el encaminamiento.
Una de las formas habituales de representar una dirección IP es utilizando cuatro octetos, por ejemplo: 138.100.52.100. En muchos casos, una dirección IP se acompaña de una máscara de subred. Se han definido redes y máscaras estandarizadas, tal y como en la tabla siguiente. [16]
|
Clase |
Formato |
Número de redes |
Número de |
Rango de direcciones de redes |
Máscara de subred |
|
A |
r.m.m.m |
128 |
16.777.214 |
0.0.0.0 - 127.0.0.0 |
255.0.0.0 |
|
B |
r.r.m.m |
16.384 |
65.534 |
128.0.0.0 - 191.255.0.0 |
255.255.0.0 |
|
C |
r.r.r.m |
2.097.152 |
254 |
192.0.0.0 - 223.255.255.0 |
255.255.255.0 |
|
D |
grupo |
- |
- |
224.0.0.0 - 239.255.255.255 |
- |
|
E |
no válidas |
- |
- |
240.0.0.0 - 255.255.255.255 |
- |
Tabla 3‑5 - Redes y máquinas estándar en Internet
Según la notación CIDR ("Classless Inter-Domain Routing"), una dirección IP se indica mediante: dirección IP/número de bits de máscara de red. Por ejemplo: La dirección IP 138.100.52.100/25, indica que la dirección de máquina es 138.100.52.100 y la máscara de subred es 255.255.255.128 (primeros 25 bits a "1"; 11111111.11111111.11111111.10000000). Por lo tanto, la dirección de red es 138.100.52.0, que corresponde a la primera de las dos subredes.
Otra manera de representar una dirección IP es mediante la base de datos distribuida DNS ("Domain Name System"). DNS se encarga de hacer traducciones entre direcciones IP y nombres de dominio (como por ejemplo mailer.upm.es).
3.1.2.5 Estructuras de datos
El Protocolo Internet (IP) añade una cabecera a los datos que recibe del nivel superior, creando un datagrama, que es el mensaje que se envía en una red de comunicaciones de ordenadores por intercambio de paquetes. La estructura de la cabecera de un Datagrama Internet es la siguiente. [17]

Figura 3‑6 - Cabecera de un Datagrama Internet
TCP también agrega su propia cabecera a los datos que recibe, con el siguiente formato. [18]
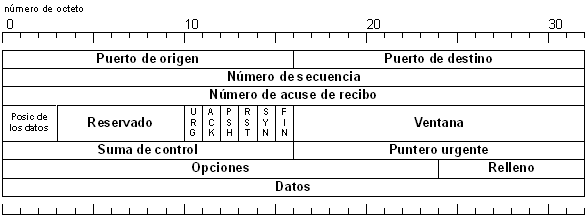
Figura 3‑7 - Formato de la cabecera de TCP
La unidad lógica de datos TCP se denomina segmento. Por otra parte, denominaremos paquete al conjunto de datos con una cabecera que puede estar o no lógicamente completa (este término se suele referir más a un empaquetamiento físico de datos que lógico).
Cuando los paquetes llegan al dispositivo de red, son encaminados hacia el destino. Una vez son recibidos, a medida que pasan por cada nivel, se retiran las cabeceras correspondientes. En el nivel de transporte, se reconstruye el datagrama a partir de los segmentos recibidos.
3.1.2.6 Captura
Una vez explicadas las estructuras de datos más utilizadas en el tráfico de red, es de rigor tratar los métodos utilizados para extraer esa información de los segmentos de red.
Captura de paquetes en sistemas Windows
Existen numerosas opciones para extraer y analizar los paquetes que pasan por un dispositivo de red utilizando estos sistemas operativos. Spynet, Iris, Windump Ethdump, Ethload, son sólo algunos de los productos que se pueden utilizar para llevar a cabo esta tarea.
Con el desarrollo del "Systems Management Server" (SMS), apareció el "Microsoft Network Monitor". Este es el rastreador de paquetes ("packet sniffer") propuesto por Microsoft. Ofrece la capacidad de capturar paquetes de red con soporte para varios tipos de protocolos, un conjunto de filtros, y la interfaz de usuario común de Windows. También ofrece la posibilidad a una máquina remota conectarse y capturar los datos locales.
Captura de paquetes en sistemas UNIX
Los sistemas UNIX cuentan con una infraestructura en materia de redes bastante más amplia y robusta que Windows. Esto no es así de forma arbitraria. No en vano, fueron los entornos más utilizados para desarrollar la mayoría de las tecnologías de red.
Los primeros trabajos en materia de captura de paquetes se atribuyen al ordenador personal Xerox Alto, que ya contaba con un filtro para monitorizar tráfico Ethernet. Este filtro fue adaptado a UNIX en 1980 por un equipo de CMU y Stanford. El "CMU/Stanford Packet Filter" (CSPF) se utilizó con éxito en un ordenador DEC PDP-11. Estaba optimizado para los ordenadores de la época.
El "Lawrence Berkeley Nacional Laboratory", notando que había problemas de ajuste entre el CSPF y las modernas CPU basadas en RISC, desarrolló el "Berkeley Packet Filter" (BPF). Este filtro aportó importantes mejoras de rendimiento frente al CSPF.
El BPF utiliza dos componentes, un "network tap" (dispositivo de escucha de red) y un filtro de paquetes. Estos datos son enviados a las aplicaciones que están en modo de escucha. Entonces, el filtro procesa la información según los parámetros enviados, y muestra los datos resultantes.
Hay dos aplicaciones de red destacables que utilizan BPF, y son tcpdump y arpwatch. Tcpdump es una herramienta de monitorización de red y adquisición de datos que permite realizar filtrados, recopilación de paquetes y visualización de los mismos. Arpwatch monitoriza la actividad que involucra los mapeos de direcciones IP y Ethernet, y avisa a los administradores cuando detecta nuevos registros o actividades anormales. [19]
Por otra parte, muchos monitores de red y programas de detección de intrusiones utilizan libpcap. Se trata de una librería de captura de paquetes, usada también por tcpdump. Libpcap es una interfaz independiente del sistema que permite hacer monitorizaciones de red a bajo nivel. Su portabilidad a distintas plataformas, como a Linux, que cada vez es más utilizado en entornos de monitorización de red y detección de intrusiones, es una de sus características más relevantes. [20]
Captura de paquetes basada en STREAMS (flujos)
STREAMS es un modelo de programación de sistemas para el desarrollo de controladores de dispositivos. La mayoría de los sistemas UNIX lo soportan (entre ellos Sun Solaris, HPX, SCO UNIX y AIX de IBM). Un "stream" (flujo) tiene una estructura de tubería ("pipe") que permite intercambiar datos con controladores de dispositivo, mediante mensajes.
La posibilidad de captura de paquetes está incluida en las librerías. Esta solución no es tan óptima como BPF. Se suele utilizar en conjunción con una interfaz proveedora de enlace de datos (DLPI), que se utiliza para funciones de rastreo. [21]
3.1.2.7 Dispositivos de red
Aparte de los rastreadores de paquetes, los propios dispositivos de red pueden aportar información de valor en materia de detección de intrusiones. Por poner un ejemplo, las estadísticas de uso pueden revelar información sobre algún posible problema de seguridad. Hay que tener presente que siempre es preferible aprovechar las fuentes de datos existentes que crear nuevos mecanismos de recopilación de datos.
3.1.2.8 Fuentes de información externas
En esta categoría entran las fuentes de información que tienen un origen manual, externo al propio sistema. La mayoría de las veces se trata de intervenciones humanas. El valor informativo aportado por el factor humano es irreemplazable. Ejemplos de este caso podrían ser entradas de registro manuales, describiendo fallos de hardware o del entorno de sistema, caídas de alimentación, análisis de eventos, o incluso comportamientos anómalos.
Un sistema de detección de intrusiones no se puede concebir en ningún caso como un sistema completamente autónomo, sino como una herramienta de diagnóstico. Permite a los administradores supervisar a alto nivel la actividad del sistema desde una perspectiva de seguridad, ayudándoles a prevenir y evitar posibles problemas.
3.1.3 Información de productos de seguridad
En la detección de intrusiones, mientras más fuentes de información existan, más posibilidades habrán de tener éxito. Muchos cortafuegos, sistemas de Inteligencia Artificial, dispositivos de seguridad y sistemas de control de acceso generan sus propios registros. Estos datos tienen evidentemente un valor importante en materia de seguridad, y junto con las otras fuentes de información ayudan a mejorar la eficacia del proceso de detección de intrusiones.
Además, los sistemas de seguridad, debido a su naturaleza, son los principales objetivos de los ataques bien planificados. Por esta razón, su monitorización y comprobación de su buen funcionamiento contribuyen a determinar la correcta estabilidad del sistema.
A continuación se describe a modo de ejemplo el formato de una entrada de registro de un producto de seguridad, concretamente el Firewall-1 de "Checkpoint Technologies". [22]
|
Número de campo |
Nombre de campo |
Contenido |
|
1 |
Número |
Identificador de transacción |
|
2 |
Fecha |
Fecha de evento |
|
3 |
Hora |
Hora de evento |
|
4 |
Acción |
Acceptar o denegar |
|
5 |
Tipo |
|
|
6 |
Origen |
|
|
7 |
Alarma |
|
|
8 |
Nombre de interfaz |
Dirección MAC o tarjeta Ethernet |
|
9 |
Dirección de interfaz |
Entrante / Saliente |
|
10 |
Tipo de protocolo |
TCP o UDP |
|
11 |
"Host" origen |
Dirección IP de origen |
|
12 |
"Host" destino |
Dirección IP de destino |
|
13 |
Tipo de servicio |
Tipo de servicio de red |
|
14 |
Numero de puerto de origen |
Puerto utilizado por el paquete |
|
15 |
"Regla" |
Regla de cortafuegos enviada |
|
16 |
Tiempo transcurrido |
Tiempo desde el comienzo de la sesión |
|
17 |
Paquetes de esta sesión |
Número de paquetes asociados a la sesión |
|
18 |
Número de bytes |
|
|
19 |
Nombre de usuario autentificado |
|
|
20 |
Mensajes |
|
Tabla 3‑6 - Formato de registro FW-1
La herramienta "fwlogsum" permite el análisis estadístico de registros generados por productos como firewall-1. Este tipo de información vuelve a poner de relieve la necesidad de algún sistema que permita la coordinación de fuentes de información de distintos orígenes. El uso del NTP ("Network Time Protocol") o alguna otra fuente fiable de información del tiempo, puede ser de gran ayuda.
3.1.3.1 Otros componentes como fuentes de datos
Entran en esta categoría otras fuentes de información, que no se consideran partes integrantes del sistema.
Uno de los ataques practicados contra los sistemas es el del enmascaramiento o suplantación de identidad. Consiste en robar la identidad de un usuario legítimo, normalmente el administrador, para entrar en el sistema. Este tipo de ataques no es fácil de detectar. Uno de los métodos para evitar este ataque, como se contempló en el capítulo 2, es el uso de técnicas estadísticas para detectar comportamientos anómalos. Es relativamente común recibir un número alto de falsos positivos mediante este método. No obstante, si se utiliza algún dispositivo externo (por ejemplo, un sistema de reconocimiento por vídeo), capaz de identificar al usuario que accede físicamente al sistema y enviar esta información al mismo, sería posible reducir de forma significativa las probabilidades de error ante este ataque.
Otro ejemplo válido es el de los ataques realizados a un sistema a través de una conexión telefónica. Una vez identificado el módem utilizado, se puede investigar el registro de la línea de teléfono implicada para averiguar la identidad del atacante. En este caso, también se ha utilizado una fuente de datos externa al sistema.
Como se ha observado, para la detección de posibles intrusiones, cualquier fuente de información puede aportar datos valiosos, y aunque no provenga de una parte legítima del sistema monitorizado, no debe ser subestimada.
3.2 Análisis
Una vez obtenidos los datos de las distintas fuentes de información en la fase de recopilación, se los somete a diversas técnicas de estudio en la fase de análisis. Para ello, la información se ordena cronológicamente, se clasifica, se evalúa de forma estadística y se identifica con patrones de actividad relativos a aspectos de seguridad. A continuación se detallarán los objetivos principales de la fase de análisis, los métodos utilizados y los requisitos necesarios para poder llevarla a cabo de forma eficaz.
3.2.1 Objetivos y elementos principales
Antes de continuar, para evitar confusiones, es conveniente definir el significado del elemento principal de esta etapa. Análisis, en el contexto de la detección de intrusiones, consiste en organizar y clasificar los datos sobre la actividad de usuario y de sistema para identificar actividades de interés [23]. En ocasiones esta actividad puede ser examinada mientras ocurre, o después de haber tenido lugar. También puede ser necesario recopilar cierta cantidad de información para poder realizar un estudio estadístico adecuado.
La Figura 3‑8 describe un modelo general de gestión de seguridad.

Figura 3‑8 - Diagrama general de un modelo de gestión de seguridad
Como se puede observar, la detección de intrusiones corresponde al segundo paso. Este diagrama es útil porque algunos mecanismos de análisis proporcionan información necesaria para los estados de investigación y recuperación del modelo.
3.2.1.1 Objetivos principales
En líneas generales, la detección de intrusiones se utiliza para mejorar la seguridad de un sistema. El análisis se lleva a cabo por una serie de motivos, entre los cuales se podrían destacar los siguientes.
· Determinar comportamientos: Una de las funciones de análisis es el estudio del comportamiento o conducta mediante funciones estadísticas. Gracias a estas funciones, se puede determinar con un porcentaje aceptable de aciertos, cuál es comportamiento normal, para así, detectar posibles intrusiones a través de variaciones en el mismo.
· Control de calidad para el diseño de seguridad y administración: Mediante el análisis se pueden detectar posibles problemas en la gestión y el diseño de la seguridad del sistema. Esto se puede aprovechar para corregir estos fallos.
· Información necesaria en intrusiones reales: En determinadas ocasiones es necesario que la información sea suficientemente detallada y fiable para poder efectuar acciones legales contra los culpables.
3.2.1.2 Requisitos y objetivos secundarios
El análisis necesita que se cumplan al menos dos características para su funcionamiento. Una de ellas es la "accountability" (responsabilidad), esto es, la capacidad de relacionar una actividad con la persona u objeto responsable de ella. Naturalmente, esto requiere un sistema fiable de identificación y autentificación del sistema. Aunque este aspecto pueda resultar trivial a simple vista, no lo es. Resulta relativamente fácil identificar las actividades de un usuario a nivel de "host", pero realizar la misma tarea a nivel de red, cuando las actividades de un mismo usuario pueden tener origen en múltiples "hosts", requiere más tiempo de proceso y mecanismos más complejos.
La otra característica es la de la detección en tiempo real y respuesta. Esto implica reconocer con rapidez los eventos generados por un intruso parar identificar un posible ataque, y reaccionar ante este, bloqueándolo (impidiendo las conexiones de red) o restaurando el sistema (ejecutando los comandos necesarios para llevar el sistema al estado de "pre-ataque").
El análisis también puede tener otros objetivos distintos a los mencionados arriba. La información puede ser utilizada para análisis forenses de red o de sistema. O puede ser necesaria para monitorizar y mejorar el rendimiento del sistema.
El siguiente paso fundamental después de determinar los objetivos y requisitos del análisis es establecer las prioridades. Las prioridades pueden ser ordenadas mediante diferentes métodos, como el horario, o el sistema ("los requerimientos de este sistema tienen preferencia sobre estos otros"). En ocasiones, algunas prioridades entran en conflicto con otras. Puede ser que almacenar los datos según unos determinados requisitos de nivel de seguridad, provoquen una caída de rendimiento que no permita efectuar análisis suficientemente rápidos.
3.2.1.3 Factores de detección
Los elementos que intervienen en el análisis de la detección de intrusiones son de diversa naturaleza. Es necesario comprenderlos mejor antes de pasar a los siguientes apartados.
· Factor humano: Los seres humanos son la fuente de información de intrusiones más común y tradicional. En lo que al análisis se refiere, existen estudios demuestran que en un escenario desarrollado durante un período de tiempo, en el que un sistema de detección de intrusiones es capaz de detectar miles de intrusiones, el ser humano sólo es capaz de detectar alrededor del 2 por ciento de las mismas.
· Eventos externos: Cualquier evento externo al sistema puede aportar información sustancial al análisis. La contratación o el despido de empleados clave en la gestión de seguridad, un inusual crecimiento de informes de anomalías de un determinado sistema o los resultados de baterías de pruebas de vulnerabilidades contra sistemas, son sólo algunos de estos ejemplos.
· Preámbulos de intrusiones: Se puede averiguar si un sistema va a ser atacado si presenta ciertas evidencias de intrusiones. Algunas de estos síntomas pueden ser la instalación de algún troyano, la adición de nuevas cuentas de usuario no autorizados al sistema o la aparición de nuevos "hosts" en el fichero de equipos de confianza (en el fichero /etc/.rhosts en sistemas UNIX, o el fichero %WINDIR%\system32\drivers\etc\hosts en sistemas Windows). Uno de los primeros proyectos de seguridad en contemplar este tipo de problemas fue COPS.
· Artefactos de intrusiones: Los ficheros de registro de un rastreador de contraseñas, fallos inexplicables del sistema, un inusual aumento del consumo de recursos o la aparición de ficheros dañados son ejemplos válidos de estos artefactos, es decir, posibles evidencias de intrusiones. Pueden utilizarse en análisis en tiempo real o en proceso por lotes. Se puede observar que algunos artefactos no han sido pensados para detectar intrusos. No obstante, ayudan en este propósito y a descubrir posibles vulnerabilidades.
· Tiempo: La posibilidad de realizar monitorizaciones en tiempo real, frente al tradicional modelo basado en proceso por lotes ("batch mode based"), hizo que la detección de intrusiones diera un paso adelante, creando nuevas vías de trabajo como mecanismos capaces de reaccionar de forma activa a ataques.
3.2.2 Modelos
Tanto la variedad como las posibilidades de los modelos utilizados en el análisis de la detección de intrusiones son enormes. Pueden ser tan simples como un sencillo "script" que procese los registros de sistema, descartando los más comunes, o tan complejos como un elaborado sistema no paramétrico entrenado con millones de transacciones.
El análisis de detección de intrusiones se puede efectuar de múltiples formas. A continuación, se mostrará el modelo propuesto por Bace [23], que intenta cubrir todas las formas de búsqueda de evidencias de intrusiones en los registros de eventos del sistema. Esto estructura el modelo en tres secciones principales: construcción del analizador, realización del análisis, y refinamiento o reestructuración del proceso. Las dos primeras secciones se dividen a su vez en dos partes: preproceso de datos y posproceso.
No toda la actividad que hay en un sistema es normal. Existe lo que se denominan anomalías ("anomalies"), que son actividades poco comunes, y usos indebidos ("misuse"), es decir, comportamientos no permitidos. La distinción entre unas y otras es absolutamente imprescindible durante el análisis. La Figura 3‑9 representa la relación que hay entre los distintos tipos de actividades de un sistema. No existe consenso en la comunidad de profesionales de seguridad en cuanto al tamaño de área de intersección entre actividades normales y usos indebidos del sistema. Algunos expertos piensan que área de intersección es mínima, mientras que otros afirman que existe una importante relación entre las dos. El debate sigue abierto, por lo que existen distintas vías de trabajo al respecto.
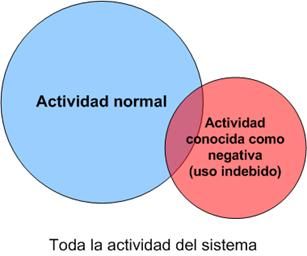
Figura 3‑9 - Actividades de un sistema: usos indebidos y anomalías
3.2.2.1 Construcción del analizador
El primer paso en el modelo es la construcción del motor de análisis. Este elemento se encarga del preproceso, clasificación y posproceso de la información. Dada su naturaleza, es necesario que esté bien adaptado al entorno en el que va a trabajar.
3.2.2.1.1 Recopilación y generación de eventos
Lo primero que hace el analizador es recopilar eventos. Esta información puede haber sido generada en un entorno de producción, en un laboratorio, o incluso hecha a mano por algún desarrollador que comprueba especificaciones.
· Detección de usos indebidos: En este caso, la recopilación se centra a información relacionada con la intrusión, incluyendo datos de vulnerabilidades, ataques, amenazas, herramientas para escanear puertos, y otras áreas de interés. También se recoge cualquier elemento sobre políticas de sistema o procedimientos que ayuden a la siguiente fase del modelo, el análisis, a discernir sobre problemas de seguridad relacionados con la organización o ataques externos.
· Detección de anomalías: Para este tipo de de detección, se recogen los eventos generados por el sistema, o por algún objetivo similar. El objetivo en este caso es poder crear un perfil, a partir de esta información, que permita diseñar un patrón de comportamiento "normal".
3.2.2.1.2 Preproceso
Después de la recopilación de los datos, se someten a una transformación, preparando los mismos. En algunos casos es necesario convertirlos a un formato canónico. Este formato suele estar integrado en el propio diseño del analizador. El término "canónico" se aplica en este caso a un formato único de estructura de datos. Hecho originado por la necesidad de facilitar la labor al motor de análisis en un entorno en que coexisten distintos sistemas operativos, cada uno con su formato de eventos nativo. En redes en las que trabajan sistemas operativos homogéneos este concepto no es necesario.
· Detección de usos indebidos: Aquí, el preproceso de datos suele consistir en la transformación de los eventos de forma que se corresponda con los datos a filtrar cuando se ponga en marcha el sistema de detección. Así, los indicios de ataques o las violaciones de las políticas de seguridad pueden ser convertidas en patrones o firmas reconocibles; y en los sistemas de detección basados en red, los paquetes pueden ser almacenados para reconstruir sesiones TCP.
· Detección de anomalías: En esta detección, los eventos se pasan a "arrays" o tablas, con algún tipo de información distintiva, como el nombre del proceso. Después de esto, se traducen a formas numéricas. El hecho de trabajar con datos numéricos reduce las necesidades de espacio, a la vez que mejora las capacidades de búsqueda e identificación de patrones en busca de problemas de seguridad.
3.2.2.1.3 Construcción de un motor o modelo de clasificación de comportamiento
Una vez se tienen los datos formateados, se hace la clasificación. Aquí se distinguen los datos que indican posibles intrusiones de los que no presentan riesgo alguno.
Detección de usos indebidos
La información se clasifica en comportamientos traducibles en patrones o reglas. Estas reglas pueden estar compuestas de una sola firma (llamadas atómicas), o de múltiples firmas (denominadas compuestas). Un ejemplo de regla atómica es la que detecta paquetes IP malformados (como aquellos con valores de campos no reconocidos por los RFC). Una regla compuesta podría consistir en la detección de un ataque a un servidor web utilizando un "exploit" consistente en una secuencia de órdenes HTTP, o un escáner que abra varios puertos que atiende el servidor.
Una de las posibles estructuras que podría tener un detector de usos indebidos es la de un sistema experto ("expert system"). Por una parte, contiene una base de conocimientos ("knowledge base") con los comportamientos sospechosos recogidos de intrusiones pasadas, y por otra, cuenta con reglas que permiten su identificación. Reglas que normalmente consisten en sentencias "if-then-else".
Otra de las estructuras más comunes es la del motor de comprobación de patrones, que representa las intrusiones como firmas de ataques (patrones) contra los que se comprueban los datos de auditoría.
Detección de anomalías
Consiste en la elaboración de perfiles estadísticos de comportamiento a lo largo del tiempo. Estos perfiles se construyen mediante determinados algoritmos, capaces de detectar cambios graduales en los patrones de conducta de los usuarios.
El "Intrusion Detection Expert System" (IDES), originado por el modelo de Denning, es un ejemplo de detector de anomalías. IDES define el comportamiento en términos de medidas ("measures"): aspectos de la conducta de usuario en los sistemas monitorizados. La Tabla 3‑7 muestra la clasificación de estas medidas. Las ordinales o continuas se expresan en forma de cantidad numérica o cuantificada. Las categóricas o discretas se expresan en forma de identidad y frecuencia de suceso.
Las categóricas están divididas en dos tipos, binarias y lineales. Las binarias indican si una medida ha ocurrido o no (positivo/falso). Las lineales se expresan en términos de cantidades, indicando el número de veces que un determinado comportamiento ha tenido lugar. [24]
|
|
Ordinal (continua) |
Categórica (discreta) |
|
Binaria |
Tiempo utilizado de CPU. Número de registros de auditoría producidos. |
Si un directorio fue utilizado. Si un fichero ha sido accedido. Si los registros de auditoría indicaron el uso por día/semana/mes. |
|
Lineal |
|
Nº de veces que cada comando fue utilizado. Nº de errores de sistema. Nº de fallos de entrada en la última hora. Nº de eventos de auditoría registrados. Nº de ficheros modificados. |
Tabla 3‑7 - Clasificación de medidas, con ejemplos, de IDES
3.2.2.1.4 Suministrar datos al modelo
Después de construir el modelo, se le pasan los datos preprocesados. Es entonces cuando se crea el motor de análisis.
· Detección de usos indebidos: A los detectores de usos indebidos se le suministran los eventos provenientes de una base de conocimiento de ataques; una recopilación de ataques en un formato que el analizador puede entender.
· Detección de anomalías: A los detectores de anomalías se le suministran los datos de referencia recopilados, permitiendo la creación de perfiles de usuario. Se suele asumir el hecho de que estos datos están libres de intrusiones, lo que implica una previa labor de comprobación de los datos recogidos.
3.2.2.1.5 Almacenar el modelo abastecido en una base de conocimientos
Este modelo constituye la base del motor de análisis. Una vez suministrados los datos pertinentes, se almacena en una localización determinada, listo para ser utilizado.
3.2.2.2 Realización del análisis
Esta es la segunda fase del analizador. Aquí es donde el analizador se aplica al flujo de datos en tiempo real para la detección de intrusiones.
· Nueva entrada de registro de evento: Lo primero que ocurre en el análisis es la llegada de un nuevo evento generado por alguna fuente de información, la cual se asume que no ha sido comprometida. El origen de este evento puede ser muy variado, como un paquete de red, un registro de auditoría de sistema,...
· Preproceso: Tal y como sucedía en la construcción del analizador, aquí también es necesario tratar los datos según las necesidades del motor de análisis. Este tratamiento puede consistir en la extracción de las cabeceras TCP de varios mensajes para definir un nivel de abstracción superior, reconstruyendo una sesión. También se puede utilizar la información de los identificadores de proceso para elaborar un esquema de proceso jerárquico superior.
· Detección de usos indebidos: Para la detección de usos indebidos, los datos se pasan a algún tipo de formato canónico, de forma que se puedan aplicar a los patrones de ataques.
· Detección de anomalías: En este caso, los datos son convertidos a perfiles numéricos con comportamientos expresados en forma de puntuaciones e indicadores.
· Contrastar los registros de eventos con la base de conocimiento: Ahora, el evento ya formateado, es comparado con la base de conocimiento. A partir de este paso, se podrán dar dos circunstancias. Una vez hecha la comparación del suceso con la base de conocimiento, si hay alguna coincidencia, el evento indica una intrusión y será registrado. Si, por el contrario, no existe, se desechará. Hecho esto, se repetirá la operación con el siguiente.
· Detección de usos indebidos: Para encontrar signos de usos indebidos, los eventos son comparados con un motor de comprobación de patrones. Si el motor encuentra una igualdad, genera una alarma. No obstante, algunos motores almacenan una equivalencia parcial (que puede indicar un posible ataque compuesto por múltiples eventos) y esperan a los siguientes datos en busca de una decisión más completa.
· Detección de anomalías: El contenido de los perfiles de comportamiento es comparado con el perfil histórico del usuario correspondiente. Según el algoritmo de análisis utilizado, se comprobará con mayor o menor exactitud el grado de similitud entre el comportamiento y el historial del usuario, generando en caso necesario la pertinente alarma.
· Generar una respuesta: Se obtiene una respuesta en caso de detectar una intrusión. La respuesta viene determinada por el tipo de analizador utilizado; puede ser una entrada de registro de sistema, una alarma, una acción de respuesta automática programada por el administrador, ...
3.2.2.3 Refinamiento y reestructuración
Algunos analizadores cuentan con una tercera fase o estado, que se ejecuta de forma simultánea con la fase principal. Consta de elementos de mantenimiento del motor de análisis y de modificación de ciertas funciones del analizador, como los patrones.
3.2.2.3.1 Detección de usos indebidos
En este tipo de detección, las funciones se centran básicamente en la modificación de los patrones para identificar nuevos tipos de ataque. Esta actualización puede ser automática o manual. Independientemente del método utilizado, se suele poder hacer "al vuelo"; no es necesario interrumpir el proceso de análisis mientras se hace la actualización.
En algunos casos, este estado se usa en conjunción con otro cuyo objetivo es el de optimizar situaciones de retención de estados, eliminando eventos que no han sido resueltos. Uno de los elementos a tener en cuenta en el análisis de usos indebidos es el tiempo. El término "event horizon" (horizonte de evento) se aplica al tiempo límite aplicable a una característica de sistema determinada, como por ejemplo la diferencia de tiempo entre dos entradas a un sistema (para detectar intentos de acceso por fuerza bruta).
3.2.2.3.2 Detección de anomalías
En este tipo de análisis, los perfiles históricos de comportamiento son actualizados de forma regular, según el tipo de motor. En el caso de IDES, los perfiles son actualizados diariamente. Después de esto, el resumen de las estadísticas de comportamiento de cada usuario es añadido a la base de conocimiento, y se eliminan las estadísticas más antiguas, como las de más de un mes. Además, a cada día se le aplica un factor de multiplicación inversamente proporcional a su antigüedad, para dar mayor valor a los comportamientos más recientes que a los ocurridos hace más tiempo. [24] Esto se hace para adaptar el sistema a los cambios de conducta graduales de cada usuario, con la intención de reducir los falsos positivos, sin que con ello se disminuya la capacidad de detección del analizador.
3.2.3 Técnicas
Una vez descrito un modelo general que abarca los tipos de análisis en la detección de intrusiones, se describirán algunas de las soluciones empleadas en este campo. Como ya se comentó en apartados anteriores, la fase de análisis se divide en dos categorías principales: la detección de usos indebidos, que compara los datos con patrones en busca de violaciones de seguridad, y la detección de anomalías, que se vale de la rama estadística de las matemáticas para identificar comportamientos sospechosos.
3.2.3.1 Detección de usos indebidos
Un detector de usos indebidos es, a grandes rasgos, un comparador de patrones. Para que funcione correctamente necesita: una base de conocimiento con patrones fiables, una serie de eventos para poder ser analizados, y un eficaz motor de análisis.

Figura 3‑10 - Modelo general de un detector de usos indebidos
La detección de usos indebidos, por su propia naturaleza, tiene una limitación importante. Y es que sólo puede identificar problemas de seguridad cuando ya se han definido en su base de conocimiento. Esto significa que se han de conocer de antemano los métodos y ataques utilizados. O bien, ser lo suficientemente inteligente como para poder anticiparse a nuevos ataques, intentando describirlos antes de que sucedan.
La detección de usos indebidos se puede implementar de las siguientes formas:
· Sistemas expertos: Aquellos que reconocen ataques o intrusiones mediante reglas "if-then-else".
· Sistemas de razonamiento basados en modelos: Usan modelos de usos indebidos junto con mecanismos de razonamiento para identificar la ocurrencia de una intrusión.
· Análisis de transiciones de estados: Hacen uso de grafos o autómatas finitos para representar y utilizar patrones de ataque.
· Monitorización de pulsación de teclas: Registran la actividad de periféricos manuales, como el teclado, para obtener información que pueda ayudar a la detección de usos indebidos.
3.2.3.1.1 Sistemas expertos o de producción
Un sistema experto, según P. Jackson, es un programa de ordenador que representa y razona con la información de un determinado tema especializado con el objeto de resolver problemas o de dar consejos [25]. Estos sistemas fueron utilizados por los primeros productos de detección de usos indebidos. Algunos ejemplos son MIDAS, IDES, "Next Generation IDES" (NIDES), DIDS, o CMDS. Sistemas de detección de intrusos basados en red como Snort y Bro, comentados más adelante, son detectores de patrones que también utilizan esta técnica.
Los sistemas de producción utilizan reglas "if-then-else" para examinar los datos. Realizan análisis mediante funciones internas al sistema, de forma completamente transparente al usuario. Antes de la existencia de los sistemas expertos, los programadores tenían que diseñar sus propios motores de decisión, lo que implicaba un trabajo adicional. Además, el hecho de que cada uno tuviera que implementar sus propios motores y reglas, impedía la llegada de una solución estándar.

Figura 3‑11 - Ejemplo de diagrama if-then-else
Una de las ventajas más importantes de utilizar reglas "if-then" es que mantiene separados el control de razonamiento y la formulación de la solución del problema. En lo que respecta a los usos indebidos, permite deducir una intrusión a partir de la información disponible.
La principal desventaja que se plantea es que los patrones no definen un orden secuencial de acciones. Detectar mediante este método ataques compuestos por una sucesión eventos encierra grandes dificultades. Por otra parte, la labor de mantenimiento y actualización de la base de datos es otros de los puntos críticos de estos sistemas.
Snort
Snort es uno de los más populares sistemas de detección de intrusiones. Aunque soporta algunas funciones de detección de anomalías, es principalmente un detector de intrusiones de red basado en reglas. Esta herramienta es Software Libre y es capaz de realizar análisis de tráfico en tiempo real, así como registrar paquetes en redes IP. Esta herramienta fue creada por Marty Roesh, que actualmente dirige el equipo de desarrollo, compuesto por expertos provenientes de diversas entidades como Sourcefire, CERT, Nitro Data Systems o CodeCraft Consultants.
Este sistema tiene la ventaja de funcionar bajo gran variedad de plataformas. Está basado en las librerías libpcap (3), de modo que admite cualquier plataforma que acepte las mismas, como las enumeradas en la siguiente tabla.
|
i386 |
Sparc |
M68k/PPC |
Alpha |
Other |
|
|
X |
X |
X |
X |
X |
Linux |
|
X |
X |
X |
|
|
OpenBSD |
|
X |
|
|
X |
|
FreeBSD |
|
X |
|
X |
|
|
NetBSD |
|
X |
X |
|
|
|
Solaris |
|
|
X |
|
|
|
SunOS 4.1.X |
|
|
|
|
|
X |
HP-UX |
|
|
|
|
|
X |
AIX |
|
|
|
|
|
X |
IRIX |
|
|
|
|
X |
|
Tru64 |
|
|
|
X |
|
|
MacOS X Server |
|
X |
|
|
|
|
Win32 - (Win9x/NT/2000/XP) |
Tabla 3‑8 - Plataformas soportadas por Snort
Snort puede realizar análisis de protocolos, búsqueda y comparación de contenidos, y puede detectar gran variedad de ataques y sondeos, tales como desbordamientos de "buffer", escaneo sigiloso de puertos ("stealth port scans"), ataques CGI, sondeos SMB, intentos de identificación de Sistema Operativo ("OS fingerprinting"), etc.
Para su labor, utiliza un lenguaje flexible de reglas para describir el tráfico de red que debe recoger o dejar pasar, además de un motor de detección que utiliza una arquitectura de "plugins" modular. Este sistema tiene también capacidades de alarma en tiempo real, y soporta diversos mecanismos de alarma, a través del "syslog", un fichero específico, sockets UNIX, mensajes WinPopup a clientes Windows, etc.
Snort tiene tres usos principales. Puede utilizarse como un rastreador de paquetes ("sniffer") de forma similar a tcpdump (4), como registrador de paquetes (útil para depuración de tráfico de red), y como detector de intrusiones de red.
Snort está escrito en código fuente abierto, y se puede obtener en su sitio oficial. [26]
Bro
Bro es un detector de intrusos en tiempo real basado en red, creado por Vern Paxson, del Laboratorio Nacional de Lawrence Berkeley y "AT&T Center for Internet Research at ICSI, Berkeley" en California. Trabaja monitorizando de forma pasiva el tráfico de red. Fue diseñado teniendo en mente estos objetivos principales:
· Monitorización de redes de alta velocidad; tipo FDDI (Fiber Distributed Data Interface), a 100 Mpbs.
· Notificación en tiempo real.
· Separación entre mecanismo y políticas.
· Extensibilidad.
Para ello, el diseño de Bro está dividido en un motor de eventos que reduce el flujo de tráfico de red filtrado, a una serie de eventos de alto nivel. Por otro lado, utiliza un intérprete de guiones de políticas que analiza los eventos, escritos en el lenguaje especializado de Bro, para expresar las políticas de seguridad del sistema. En la siguiente figura se muestra la estructura general del sistema.

Figura 3‑12 - Estructura de Bro
Bro no sólo detecta ataques realizados a través del tramo de red que monitoriza, sino que también contempla la posibilidad de ser en sí mismo un potencial objetivo de ataques. Para ello, cuenta con mecanismos específicos para su detección y defensa. Algunos de los ataques que reconoce son:
· Sobrecarga: cuyo objetivo es sobrepasar la capacidad de proceso del detector.
· Caída: provocan fallos en el monitor, o lo dejan sin recursos de sistema.
· Subterfugio: intentan engañar al monitor mediante el envío de paquetes TCP con sumas de control inválidas, o paquetes IP cuyo TTL (Tiempo de vida) es suficiente para llegar al monitor, pero no para llegar a su destino.
Aparte de esto, y para ampliar su grado de efectividad, Bro también cuenta con capacidades de proceso específico de algunas aplicaciones de red, tales como: Finger, FTP, Portmapper, Ident, Telnet y Rlogin.
Bro se distribuye bajo una licencia tipo BSD; es Software Libre, pero no copyleft. [27]
3.2.3.1.2 Sistema basado en modelos
Este sistema, que consiste en una variación de la detección de usos indebidos, fue propuesto por T.D. Garvey y T. Lunt. Utiliza una base de datos de escenarios de ataque, en la que cada escenario consiste en una secuencia de comportamientos que forman el ataque. En cada momento, el sistema analiza subconjuntos de comportamientos de su base de datos que coincidan con los que está experimentando en ese instante. Utiliza los resultados para identificar y anticipar posibles ataques (anticipador). El anticipador determina las posibles hostiles y las envia al planificador. Este planificador determina el grado de acierto entre el comportamiento recibido y el que figura en los registros de auditoría, y traduce los resultados en registros de auditoría del sistema.
La ventaja de este modelo radica en que está basado en una teoría matemática que utiliza el principio de incertidumbre. El diseño del planificador es independiente de la sintaxis del registro de auditoría. Además de esto, esta solución consume poco tiempo de proceso por cada registro de auditoría generado.
Un inconveniente que presenta este modelo es que depende de la buena pericia del encargado de seguridad a la hora de diseñar patrones creíbles y precisos. Por otra parte, el modelo no especifica claramente la forma en que se deben compilar los comportamientos en el planificador para que sea más eficiente, lo que afecta al rendimiento del detector. Esto no es una debilidad inherente al modelo, pero es algo a tener en cuenta en la implementación.
3.2.3.1.3 Transiciones de estados
El uso de transiciones de estados ("state transitions") para la detección de usos indebidos permite trabajar con técnicas avanzadas de comprobación de patrones. Se utilizan estados y transiciones del sistema para definir y encontrar intrusiones.
Entre los métodos que adoptan esta metodología destacan tres: el análisis de transiciones de estados, las "Colored Petri Nets" (CP-Nets), y el "Aplication Programming Interface" (API).
Análisis de transiciones de estados
Este análisis utiliza diagramas de transiciones de estados que representan ataques conocidos para la detección de usos indebidos. Este método fue utilizado por primera vez por el sistema STAT [28], portado a redes UNIX bajo el nombre de USTAT [29]. Estos sistemas fueron creados en la Universidad de California.
Los diagramas de transición, como ilustra la Figura 3‑13, son representaciones gráficas de escenarios de intrusiones. Utilizan autómatas finitos (grafos) para los ataques. El paso por cada estado depende de que se cumplan o no una serie de características.

Figura 3‑13 - Diagrama de transiciones de estados
Los nodos representan los estados, y las flechas (arcos) las transiciones. Utilizar diagramas de transición facilita la asociación entre los estados y los distintos pasos que realiza un intruso desde que entra en un sistema, con privilegios limitados, hasta que se hace con el control del mismo.
Los estados del diagrama indican situaciones particulares de un sistema, a las que se puede llegar de distintas maneras. De esta forma, varios atacantes pueden confluir en el mismo estado habiendo realizado diferentes pasos.
El estado inicial representa el estado del sistema antes de ser comprometido. La intrusión se produce cuando se llega al último estado del diagrama. Las transiciones ocurren por acciones del usuario. El sistema comprueba su esquema de transiciones para determinar a qué estado se llega. Si una acción determinada no lleva a ningún estado en concreto, el sistema devuelve al usuario al estado más cercano en que estaba. Si las acciones llevan al usuario al estado final de un diagrama, el sistema envía una alarma al responsable de seguridad con las acciones tomadas en la última transición.
Algunas de las ventajas del STAT son las siguientes:
· Los diagramas de transición permiten hacer una representación a alto nivel de escenarios de penetración.
· Las transiciones ofrecen una forma de identificar una serie de patrones que conforman un ataque.
· El diagrama de estados define la forma más sencilla posible de definir un ataque. Así, el motor de análisis puede utilizar variantes del mismo para identificar ataques similares.
· El sistema puede detectar ataques coordinados y lentos.
Estas son algunos de los inconvenientes del STAT:
· Los diagramas de transición y las firmas o patrones son creados a mano.
· El lenguaje utilizado para describir los ataques es demasiado limitado, y en ocasiones puede resultar insuficiente para recrear ataque más complejos.
· El análisis de algunos estados puede requerir más datos del objetivo, por parte del motor. Esto reduce el rendimiento del sistema.
· Las limitaciones de este sistema hace que no pueda detectar algunos ataques comunes, siendo necesario el uso de motores de análisis adicionales.
IDIOT y "Colored Petri Net"
"Coloured Petri Nets" (CP-nets o CPNs) es un lenguaje orientado a objetos para el diseño, especifiación y verificación de sistemas. Es especialmente apropiado para sistemas formados por gran variedad de procesos que necesitan estar comunicados y sincronizados. Algunas áreas típicas en las que se aplica este lenguaje son sistemas distribuidos, protocolos de comunicación, o sistemas de producción automática.
La siguiente figura muestra algunas de los modelos de operaciones contemplados por el lenguaje Petri-net.
Figura 3‑14 - Modelo Petri-net
IDIOT (5) fue desarrollado en la Universidad de Purdue, y representa sus patrones de intrusiones mediante el lenguaje de estados y transiciones definidos por CPNs. [31]
Aunque el sistema STAT y el IDIOT puedan parecer iguales, no es así. Existen importantes diferencias entre ambos puntos de vista. En STAT las intrusiones son detectadas por el impacto que tienen sobre el estado del sistema, en IDIOT las intrusiones se detectan mediante la comparación de los patrones que forman el ataque. En STAT, los detectores ("guards") están ubicados en los estados, mientras que en IDIOT están en las transiciones.
En el sistema IDIOT las intrusiones se expresan en forma de patrones que representan relaciones entre los eventos de sistema y su contexto. Este método es independiente de la arquitectura del sistema, y permite representar cualquier categoría de intrusiones. El siguiente ejemplo consiste en un patrón creado mediante el lenguaje Petri-net para la detección de repetidos intentos de acceso fallido.
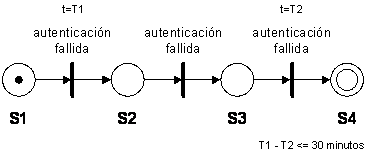
Figura 3‑15 - Ejemplo de patrón de ataque mediante el lenguaje Petri-net
Una de las ventajas del sistema IDIOT es que es muy rápido; consume menos del 5% del tiempo de CPU en una estación Sun SPARC 5 que genera alrededor de 6 MB por hora. El motor encargado de la comparación de patrones es independiente de la plataforma en que trabaja. Esto hace que las firmas que utiliza se puedan intercambiar entre distintos sistemas, independientemente de la sintaxis de registros de auditoría usada. Además, soporta respuestas automáticas; permite especificar las acciones que se ejecutarán en caso de detectar intrusiones.
Las desventajas son las mismas que tienen los sistemas de detección de usos indebidos. No puede detectar lo que no está definido en sus bases de patrones.
3.2.3.1.4 Soluciones basadas en Lenguaje/API
Otra de las formas de abordar el problema de los usos indebidos es definir lenguajes específicos para los motores de detección de intrusiones. Esta opción es mejor que utilizar otros lenguajes ya existentes como P-BEST o CLIPS, diseñados para otros fines.
Algunas de las soluciones basadas en este método son el lenguaje RUSSEL, desarrollado en la Facultad Universitaria de Notre-Dame de la Paix [32]; el sistema STALKER, ilustrado en la figura de abajo, patentado por Smaha y Snapp de los Laboratorios Haystack [33]; el lenguaje de filtrado de paquetes N usado como parte del NFR (Network Flight Recorder) [34]; el lenguaje ASL, escrito en la Universidad de Iowa; o el IMDL (Intrusion Detection Markup Language), creado en la Universidad Nacional de Chiao Tung [35].
Figura 3‑16 - Arquitectura del sistema STALKER
3.2.3.1.5 Monitorización de teclado
Esta técnica consiste en recoger las pulsaciones de teclado para obtener datos que puedan revelar indicios de alguna intrusión.
La principal ventaja de esta solución es que registra toda la actividad tecleada en una sesión interactiva, cosa que está fuera de las posibilidades de los registros de sistema o de auditoría.
Desgraciadamente, existen ataques que no hacen uso del teclado. Además, la misma intrusión se puede expresar de múltiples formas a nivel de pulsaciones de teclas. Si no se hace un análisis semántico de la información obtenida es casi imposible detectar un ataque mediante este método.
3.2.3.1.6 Recuperación de información en modo "batch"
Antes de pasar al siguiente apartado, hay que explicar que los modelos vistos anteriormente trabajan en tiempo real. No obstante, hay soluciones que buscan información adicional en los ficheros de sistema, una vez que el ataque se ha producido. Esto es especialmente útil para expertos de seguridad especializados en el área forense.
Un modelo basado en técnicas IR ("Information Retrieval"), utilizado en algunos motores de búsqueda en Internet como Altavista, es el propuesto por Ross Anderson y Abida Khattak de la Universisdad de Cambridge.
Su solución utiliza el registro de sistema UNIX lastcomm en conjunción con GLIMPSE, un motor de búsqueda de la Universidad de Arizona. Un guión basado en Perl divide el registro en ficheros únicos para cada usuario. Sobre estos ficheros se ejecutan búsquedas de GLIMPSE relacionadas con los ataques recibidos. Este método sencillo permite encontrar rápidamente información extra sobre las incidencias detectadas. Otra de las ventajas de este enfoque, es que no tiene coste alguno. GLIMPSE es gratuito, y se incluye por defecto en algunos sistemas. [36]
3.2.3.2 Detección de anomalías
En la detección de anomalías se utilizan diversos algoritmos para crear perfiles de comportamiento normal, que sirvan de modelos a contrastar con la conducta actual de cada usuario. Las desviaciones que resultan de esta comparación son sometidas a técnicas que utiliza el sistema para decidir si ha habido o no indicios de intrusiones. Los perfiles están compuestos por conjuntos de métricas. Las métricas son medidas sobre aspectos concretos del comportamiento del usuario.

Figura 3‑17 - Modelo general de un detector de anomalías
El principal inconveniente de la detección de anomalías es que los perfiles de conducta pueden ser gradualmente educados. Un atacante que sepa que sus actividades están siendo monitorizadas, puede cambiar paulatinamente su forma de comportamiento a lo largo del tiempo, para que cuando cometa una intrusión no sea reconocida como tal. Esta técnica es conocida como "session creep" (deslizamiento, o movimiento sigiloso de sesión).
Por otra parte, una de las ventajas la detección de anomalías consiste en su posibilidad de descubrir nuevos ataques, ya que se adapta y aprende de la conducta del sistema, al contrario que la detección de usos indebidos.
3.2.3.2.1 Modelo de Denning
Dorothy Denning indica en su documento "An Intrusion Detection Model" al menos cuatro modelos estadísticos que deben estar presentes en el sistema. Cada uno diseñado para adoptar un determinado tipo de métrica [37]. Estos modelos son:
Modelo operacional
Se aplica sobre eventos para determinar por ejemplo, el número de intentos de acceso fallidos al sistema. Compara su métrica con un valor umbral, que normalmente le indica si se ha cometido una intrusión. Este modelo también es aplicable a la detección de usos indebidos, y es el desarrollado en la detección de umbral, explicada más adelante.
Modelo de desviación media y estándar
Este modelo aplica el concepto de desviación media y estándar típico a la hora de elaborar los perfiles de comportamiento. Supone que a partir de las dos primeras medidas, se puede establecer un intervalo de confianza. Este intervalo sirve para determinar la desviación estándar. Si las siguientes medidas caen fuera de este intervalo revelarían un comportamiento anormal.
Modelo multivariable
Es una ampliación del modelo de desviación media y estándar. Utiliza correlaciones entre dos o más métricas para definir un comportamiento. Por ejemplo, en vez de determinar la conducta de un usuario exclusivamente por la duración de su sesión, también se tiene en cuenta la actividad de tráfico de red que genera durante la misma.
Modelo del Proceso Markov
Este es el modelo más complejo de los cuatro. Considera cada evento de auditoría como una variable de estados, y utiliza una matriz de transiciones de estados para describir la frecuencia de transiciones de estados (no la de cada evento, sino la de todos juntos). Un evento determinado indica una anomalía si su probabilidad es demasiado baja. Este modelo ayudó a desarrollar análisis basados en flujos de eventos o la generación patrones probables ("predictive pattern generation") comentada más adelante en esta sección.
3.2.3.2.2 Análisis cuantitativos
Probablemente, las técnicas basadas en análisis cuantitativos son las más utilizadas para la detección de anomalías. Mediante este método, las reglas de detección y los atributos de los objetos se expresan en forma numérica. Estos elementos se utilizan en análisis de diverso grado de complejidad. Los resultados se pueden usar para aportar patrones a la detección de usos indebidos, o para elaborar perfiles relativos a la detección de anomalías. A continuación se describen algunos ejemplos de este tipo de análisis.
Detección de umbral
Este sistema es conocido también como detección de umbral y disparador ("threshold and trigger"). En este caso, se cuenta el número de veces que ocurren los elementos que forman los perfiles de cada usuario, y se comparan estos datos con valores de umbral. Por ejemplo, si un usuario ha intentado entrar en el sistema más de cinco veces seguidas con una contraseña incorrecta, hay probabilidad de intrusiones. O si se realiza una serie de intentos de apertura de puertos en un intervalo de tiempo inferior a un límite, es posible que se esté intentando escanear el sistema.
Detección heurística de umbral
Esta detección desarrolla el punto de vista anterior, adaptando los valores de umbral a las medidas experimentadas. Por ejemplo, si un usuario suele entrar al sistema por lo general al primer o segundo intento durante un período de tiempo determinado, y en una determinada ocasión se produce un inusual número de intentos fallidos, se produce una anomalía. Los métodos que se utilizan para aproximar el valor de umbral son de diversa naturaleza. Uno de los más simples y conocidos puede ser el de la función de campana de Gauss. Todos aquellos valores que se alejen demasiado de lo definido como normal, revelan una posible intrusión.
Chequeos de integridad basados en objetivo
Consiste en utilizar alguna técnica que permita determinar si el objetivo monitorizado ha cambiado. Normalmente se utilizan funciones de resumen criptográfico ("hash") sobre los objetivos, para generar sumas de control ("checksum") almacenadas en una base de datos protegida. Si el objetivo en cuestión ha cambiado lo más mínimo, su suma de control habrá cambiado sustancialmente con respecto a la anterior. Uno de los productos comerciales más populares que utilizan este método es Tripwire®.
Reducción de auditoría
La reducción de eventos fue uno de los aplicaciones que tuvo el análisis cuantitativo. Este concepto, aparecido en el apartado 3.1.1.3, consiste en la eliminación de información redundante o irrelevante existente en registros de sistema de gran tamaño. Este proceso permite un análisis posterior más rápido y eficiente.
El sistema NADIR, desarrollado en la División Computacional y de Comunicaciones del Laboratorio Nacional de Los Alamos, es un ejemplo de un producto que utiliza este enfoque. NADIR transforma los registros de auditoría en vectores, y los somete a un proceso de reducción de datos. El resultado es examinado mediante análisis estadísticos y sistemas expertos supervisados por un operador. [38]
3.2.3.2.3 Medidas estadísticas
Las medidas estadísticas constituyen uno de los primeros métodos utilizados para la detección de anomalías. Muchos de los productos de detección de intrusiones basados en red utilizan esta técnica. Suelen servirse de filtros de anomalías de protocolo [39], que en realidad son filtros de anomalías estadísticas, adaptados para trabajar con protocolos de red.
El término filtro de anomalías estadísticas, se utiliza para definir sistemas que buscan eventos cuyo valor estadístico es inusualmente bajo, haciéndolos sospechosos. Un filtro de anomalías de protocolo, es un tipo de filtro de anomalías estadísticas al que se ha añadido información específica sobre protocolos de red. En el diagrama siguiente se puede observar la relación entre las áreas identificadas como definiciones oficiales de protocolos, el uso práctico de estos protocolos, y los ataques o intrusiones. Gran parte de los ataques que se producen, son debidos a usos anómalos de los protocolos. Casi todos los ataques explotan las debilidades existentes, tanto en las definiciones oficiales como en algunas implementaciones de los protocolos. Los filtros de anomalías de protocolo son capaces de detectar aquellos ataques realizados fuera del área de uso normal.
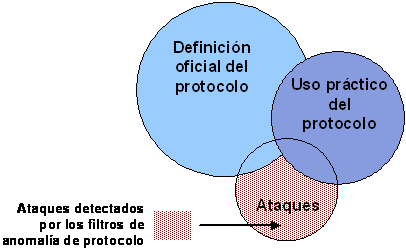
Figura 3‑18 - Ataques que detecta un filtro de anomalías de protocolo
Algunos de los sistemas que utilizan medidas estadísticas están basados en frecuencia, en los que la frecuencia con la que se da un determinado evento determina su probabilidad. Algunos de los sistemas partidarios de esta idea son el sistema IDES (utilizado en el proyecto NIDES), el sistema Haystack, SPADE, o ADAM, descritos más adelante.
Más tarde comenzaron a hacer aparición acercamientos basados en tiempo, en los que lo que determina la probabilidad de un evento es el tiempo transcurrido desde que sucedió por última vez. Sistemas como PHAD, ALAD, LERAD o NETAD son algunos de los partidarios de este enfoque, explicados más abajo en esta sección.
Haystack
Haystack fue creado por Tracor Applied Sciences y los Laboratorios Haystack para las Fuerzas Aéreas norteamericanas [40]. Incorpora dos mecanismos estadísticos para la detección de anomalías. El primero investiga el grado de similitud entre una sesión de usuario y una intrusión conocida. Esto lo hace aplicando diversos algoritmos a vectores del comportamiento de usuario, y relacionado los resultados con puntuaciones obtenidas de intrusiones ya establecidas. El segundo, de forma complementaria, calcula la desviación entre las estadísticas obtenidas de la sesión actual del usuario y los datos de su perfil estadístico histórico. [41]
IDES/NIDES
Ambos sistemas fueron desarrollados por SRI International. Utilizan tanto detección de usos indebidos como de anomalías. En lo que respecta a la detección de anomalías, se hace uso de perfiles estadísticos históricos, para cada usuario y sistema. Estos perfiles se actualizan con el paso del tiempo según los cambios de comportamiento.
El sistema IDES utiliza una base de conocimiento estadística con los perfiles obtenidos. Cada perfil contiene su conjunto de métricas. Esta estadística, denominada puntuación IDES (IS), se calcula utilizando la fórmula:
IS = (S1,S2,...,Sn)C-1(S 1,S2,...,Sn)t
En la que C-1 es la inversa de la matriz de correlaciones del vector (S1,S2,...,Sn), y (S1,S2,...,Sn)t es la transpuesta de ese vector. Cada medida Sn representa elementos de comportamiento, tales como tiempo de sesión, número de intentos de acceso fallido, consumo de CPU, uso de la red. [42]
SPADE / SPICE
Ambos productos han sido desarrollados por Silicon Defense. SPADE (Statistical Packet Anomaly Detection Engine) es un preprocesador de datos que permite la detección de paquetes sospechosos utilizando técnicas de detección de anomalías. Se puede ejecutar como "plugin" del Snort.
El sistema SPICE (Stealthy Probing and Intrusion Correlation Engine), está formado por dos elementos: el ya mencionado detector de anomalías SPADE, y un correlacionador de eventos.
El funcionamiento consiste en la detección de anomalías por parte de SPADE, las cuales envía al correlacionador. Una vez relacionadas y agrupadas, el correlacionador las registra, comunicando las posibles actividades sospechosas. El correlacionador es capaz de detectar por ejemplo, escaneos de puertos en orden aleatorio, demasiado lentos, o incluso aquellos realizados desde distintas fuentes. [43]
ADAM
Este sistema, al igual que NIDES o SPADE, es un detector de anomalías basado en frecuencia, es decir, estima la probabilidad de cada evento según con la frecuencia que ocurra. Como el resto de los sistemas de su categoría, no necesita bases de datos de firmas para reconocer actividades inusuales.
Puede ser entrenado para identificar tanto ataques conocidos como los aún no publicados. Identifica las posibles intrusiones marcando cualquier actividad que no ha aprendido como anómala. [44]
PHAD [45], ALAD [46], LERAD [47]
Estos métodos de detección de anomalías de red están basados en tiempo, de modo que determinan la probabilidad de un evento según el tiempo que ha pasado desde que tuvo lugar por última vez. Fueron diseñados por Matthew V. Mahoney y Philip K. Chan en el Institute of Technology de Florida.
Utilizan el concepto de atributo para analizar el tráfico de red. Los atributos son normalmente datos obtenidos de los paquetes de red, como los campos de cabecera.
Para cada atributo, recopilan un conjunto de valores permitidos (cualquier cosa observada al menos una vez durante el entrenamiento o aprendizaje), y marcan aquellos valores nuevos como anómalos. Utilizan la siguiente ecuación para puntuar los atributos nuevos:
∑ tn /r
Donde t es el tiempo transcurrido desde que el atributo fue identificado como anómalo por última vez, n el número de entrenamientos realizados, y r el tamaño del conjunto de valores permitidos. De esto se puede deducir que r/n es el valor medio de anomalías detectadas durante entrenamientos. Además, el factor t hace que el modelo sea dependiente del tiempo, otorgando mayores valores a aquellos atributos que llevan más tiempo sin ocurrir.
Las diferencias entre los sistemas PHAD, ALAD y LERAD radican en los atributos que monitorizan. PHAD ("Packet Header Anomaly Detector") contempla 34 atributos correspondientes a las cabeceras de paquetes Ethernet, IP, TCP, UDP e ICMP. ALAD ("Application Layer Anomaly Detector") construye modelos a partir de las peticiones TCP entrantes, formados por las direcciones origen y destino, los puertos utilizados, los indicadores TCP, y los comandos existentes en el campo de datos de aplicación. Puede llegar a construir modelos independientes para cada "host", puerto o combinación de ambos. LERAD ("LEarning Rules for Anomaly Detection") también construye modelos TCP, pero utiliza los datos obtenidos para sugerir modelos. Por ejemplo, si registra dos peticiones FTP, destinadas al mismo "host", puede sugerir una regla que indica que todas las peticiones hacia ese "host" deben ser FTP y construye un modelo de puerto para ese "host".
NETAD
El sistema NETAD ("Network Traffic Anomaly Detector") fue escrito por Matthew V. Mahoney en el Institute of Technology de Florida. Es muy similar a PHAD, pero fue diseñado para mejorar algunas de sus características. [48]
Utiliza la detección de anomalías en paquetes de red, y está basado en tiempo. No obstante, cuenta con algunas características que lo diferencian de PHAD:
· Filtra el tráfico, examinando sólo el comienzo de las peticiones entrantes.
· Utiliza como atributos los primeros 48 bytes de los paquetes que comienzan con cabeceras IP.
· Cuenta con 9 modelos distintos correspondientes a los protocolos más utilizados, como IP, TCP o HTTP.
· La ecuación tn/r para determinar las anomalías ha sido modificada para indicar sucesos poco comunes, pero no necesariamente anómalos.
La mayoría de los ataques comienzan mediante el envío de peticiones a un servidor o sistema operativo, por lo que para su detección suele ser suficiente analizar el comienzo de las peticiones enviadas a la víctima. NETAD utiliza diferentes métodos para esta tarea: descarta paquetes que no sean IP, tráfico saliente (no detecta las respuestas anómalas de un servidor), las conexiones TCP entrantes que comienzan con indicadores SYN-ACK activados (indicando que la conexión ha sido iniciada por un "host" local), etc.
Los atributos de NETAD están compuestos por los primeros 48 bytes de los paquetes que comienzan con una cabecera IP. Por ejemplo, en un paquete TCP normal, los atributos son los 20 bytes de cabecera IP, otros 20 bytes de cabecera TCP, y los 8 primeros bytes del campo de datos de aplicación.
Los 9 modelos construidos por NETAD son 9 subconjuntos de tipos de paquetes comunes, obtenidos del tráfico de red. Algunos de estos modelos son: todos los paquetes IP (incluyendo TCP, UDP e ICMP), todos los paquetes TCP, todos los paquetes TCP SYN (sin otro indicador, es normalmente el primer paquete, con opciones TCP y sin campo de datos), todos los paquetes TCP ACK (normalmente el segundo y siguientes paquetes, que contienen campo de datos), paquetes TCP ACK a puertos 0-255, TCP ACK al puerto 21 (FTP), etc. Es posible que un paquete pueda pertenecer a más de un subconjunto. Por ejemplo, un paquete de datos FTP, también es TCP a puertos 0-255, TCP ACK, TCP e IP.
NETAD utiliza la siguiente versión modificada de la puntuación de anomalías tn/r (adoptada por PHAD, ALAD y LERAD):
∑ tna(1 – r/256) + ti(fi + r/256)
Donde na es el número de paquetes de entrenamiento transcurridos desde la última anomalía hasta el final del período de entrenamiento, t el período de prueba, r el número de valores permitidos (entre 1 y 256), ti el tiempo transcurrido desde que fue contemplado el valor i (entre 0 y 255) tanto durante entrenamientos o pruebas, y fi la frecuencia con la que ha ocurrido el valor i durante el entrenamiento. Una de las ideas destacables de este modelo de puntuación, es que tiene en cuenta el concepto de frecuencia, cosa que no hacen PHAD, ALAD o LERAD.
Ventajas e inconvenientes de las medidas estadísticas
Las medidas estadísticas para la detección de intrusiones, están entre las técnicas más utilizadas. Sin embargo, no por ello dejan de tener sus inconvenientes. Aquí se enumeran las características más relevantes, tanto positivas como negativas.
La ventaja más conocida, y quizás la más importante de los métodos basados en análisis estadísticos, es su capacidad para la detección de nuevos ataques. Los filtros de anomalías de protocolo, mencionados antes, pueden detectar nuevos ataques, aún sin haber sido registrados por las entidades oficiales de seguridad. No necesitan actualizar ninguna base de datos de firmas. En ese aspecto, son superiores a los sistemas de detección basados en patrones.
Otra de las características, derivada de la anterior, de los sistemas estadísticos es que no requieren el mantenimiento que necesitan los sistemas de detección de usos indebidos. No utilizan bases de firmas o patrones. Esto implica, por supuesto, contar con un modelo que utilice las métricas precisas, y que se adapte adecuadamente a los cambios de comportamiento de los usuarios.
Uno de los inconvenientes que más se achacan a la detección de anomalías mediante medidas estadísticas, es que puede ser paulatinamente entrenada, cosa que no ocurre con la detección de usos indebidos. Un usuario malicioso que supiera que está siendo monitorizado, podría cambiar intencionadamente su actitud para que, en un momento dado, el sistema identificara como normal un comportamiento hostil.
Otro de los inconvenientes de estos sistemas radica en el gran consumo de recursos que utilizan frente a otros modelos propuestos. Los análisis estadísticos normalmente requieren más tiempo de proceso que los sistemas de detección de usos indebidos. Esta limitación fue una de las razones por las que los primeros sistemas estadísticos se ejecutaban en modo "batch" antes de poderse realizar en tiempo real.
Por otra parte, la naturaleza de los análisis estadísticos les impide tener en cuenta relaciones entre eventos secuenciales. El orden de ocurrencia de eventos no suele ser uno de los atributos utilizados por los modelos de análisis estadísticos. No pueden reconocer directamente ataques realizados mediante sucesiones de eventos en un determinado orden. Esto representa una seria limitación, dado el elevado número de intrusiones basadas en estas características.
En muchos sistemas basados en medidas estadísticas, el número de falsas alarmas es demasiado alto, lo que hace que muchos usuarios las ignoren.
3.2.3.2.4 Medidas estadísticas no paramétricas
Los sistemas estadísticos pueden ser de tipo paramétrico o no paramétrico. Los primeros son aquellos cuyas distribuciones son conocidas de antemano. Por ejemplo, en las primeras versiones de IDES, la distribución utilizada era la Gaussiana o normal. La mayoría de los primeras soluciones basadas en medidas estadísticas utilizaban aproximaciones de tipo paramétrico.
Los enfoques estadísticos no paramétricos, por tanto, trabajan con perfiles de comportamiento que no se basan en distribuciones preestablecidas.
El inconveniente de los métodos paramétricos es que las tasas de error en algunos casos es demasiado alta. Si una determinada métrica, como el consumo de CPU, no se ajustaba a una distribución conocida como, por ejemplo, la normal, se producían demasiados errores.
En la Universidad de Tulane, Linda Lankewicz y Mark Benard propusieron un modelo de detección de anomalías basado en técnicas no paramétricas [49]. Esta solución utiliza patrones de uso menos predecibles y permite tener en cuenta medidas difíciles de utilizar en enfoques paramétricos.
Los datos se clasifican mediante una técnica denominada "clusterig analysis" (agrupación de datos). La información histórica se agrupa y organiza en "clusters" (grupos) según diversos criterios de evaluación (llamados "features"). Los datos asociados a un determinado usuario u objeto son preprocesados y convertidos en representaciones vectoriales (por ejemplo Xi = [f1, f2, ..., fn]). Luego, mediante un algoritmo de agrupación, esos vectores se reúnen en clases de comportamiento. La idea es que aquellos miembros de una clase estén muy relacionados unos con otros, mientras que los de clases diferentes sean lo más distintos posible.
Siguiendo este modelo no paramétrico, la actividad de un usuario, expresada en términos de criterios de evaluación, se divide en dos grupos principales: uno que indica actividad anómala, y otro que indica actividad normal.
Una de las ventajas de modelos no paramétricos es que hacen una efectiva reducción de datos de auditoría, mediante la transformación de eventos en vectores. Por otra parte, tienen mayor velocidad de detección que los análisis estadísticos paramétricos.
No obstante, un consumo de recursos excesivo, por parte de los criterios de evaluación, reduciría de forma notable la eficiencia de sistemas basados en este tipo de análisis.
3.2.3.2.5 Sistemas basados en reglas
Otra de las aproximaciones de la detección de anomalías es la basada en reglas ("rule-based"). Utiliza los mismos métodos que la detección de anomalías estadística. La diferencia radica en que la detección de intrusiones basada en reglas hace uso de conjuntos de reglas para representar y almacenar patrones de uso. Algunos de los sistemas que utilizan esta metodología son Wisdom and Sense, o TIM (Time-Based Inductive Machine).
Wisdom and Sense
"Wisdom and Sense" (Sabiduría y sentido), fue desarrollado en el Laboratorio Nacional de Los Alamos y el Laboratorio Nacional de Oak Ridge [50]. Soporta gran variedad de plataformas y puede trabajar a nivel de sistema operativo y de aplicación.
Tiene dos formas de añadir reglas a la base de datos: de forma manual, o mediante generación automática a partir de los datos históricos de auditoría. La reglas reflejan el comportamiento de los usuarios y objetos y están almacenadas en una estructura de árboles denominada bosque. Algunos datos específicos dentro de los registros de auditoría se agrupan en "thread classes" (clases de hilo) a las que se asocian conjuntos de operaciones o reglas. Una "thread class" podría ser "los registros asociados a un determinado usuario".
Las anomalías se detectan al comparar los nuevos eventos con aquellos asociados a los "threads" correspondientes, y evaluando su relación con los patrones históricos de actividad.
Generación de patrones probables
La generación de patrones probables o "Predictive Pattern Generation" intenta predecir eventos futuros basándose en aquellos que ya han tenido lugar [51]. Utiliza una base de reglas de perfiles de usuarios definida a partir de estadísticas de eventos. La Figura 3‑19 muestra un ejemplo de una posible regla creada mediante esta metodología:
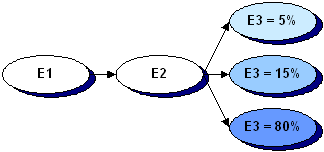
Figura 3‑19 - Generación de patrones probables
Esto significa que, contando con la premisa de que los eventos E1 y E2 han ocurrido en ese orden, hay un 80% de probabilidades de que siga E3, un 15% de que ocurra E4, y un 5% de que tenga lugar E5. No obstante, algunas de las intrusiones que no figuren en las reglas no se reconocerán como tales. Por lo tanto, si una secuencia de eventos determinada existe, y pertenece a una intrusión, pero no está en la base de reglas, se marcará como no reconocida. Esto se puede arreglar marcando los eventos no reconocidos como intrusiones, aunque esta medida también aumentará el número de falsos positivos. Normalmente, un evento se marca como intrusión si la parte izquierda de la regla coincide, pero la parte derecha es muy diferente de la predicción estadística.
Este método tiene numerosas ventajas. Una de ellas, es que puede detectar anomalías en secuencias de eventos, difíciles de detectar mediante otros métodos menos flexibles. Por otra parte, adapta con facilidad a los cambios de comportamiento. Los patrones menos utilizados son paulatinamente eliminados, quedando a largo plazo aquellos de más calidad. Mediante esta técnica es más fácil identificar a aquellos usuarios que intentan entrenar al sistema durante su fase de aprendizaje (método ya comentado, denominado "session creep"). Esto es así, debido a que la semántica se construye en las propias reglas de detección. Además, este método tiene pocos requerimientos de recursos de sistema, haciendo posible el proceso de los datos de auditoría e identificación de anomalías en poco tiempo.
Uno de los inconvenientes de estos sistemas es que, como ocurre con todos los sistemas de aprendizaje, dependen de la calidad del material de entrenamiento que usan. Los datos de aprendizaje deben ser lo más fieles posibles a la actividad normal de los usuarios. Además, el número de falsos positivos es grande principalmente al comienzo de la operación, debido a que la mayoría de los eventos existentes no suelen coincidir con los comienzos de las reglas.
TIM
El sistema TIM ("Time-Based Inductive Machine") fue desarrollado por Teng, Chen y Lu en asociación con Digital Equipment Corporation [52]. Utiliza métodos inductivos para generar secuencias de patrones. Implementa un tipo de modelo de probabilidad de transiciones de Markov de Denning, buscando patrones en secuencias de eventos.
Su funcionamiento y características están basados en la técnica de generación de patrones probables, explicada antes. Como TIM utiliza grupos de secuencias de eventos, el espacio que necesita para su base de reglas es menor que el que necesitan aquellos sistemas que trabajan con eventos aislados, como Wisdom and Sense.
Este producto sentó las bases del producto de detección de intrusiones Digital Equipment Corporation Polycenter y sirvió de referencia para muchos trabajos sobre detección de anomalías posteriores.
3.2.3.2.6 Redes neuronales
Una de las formas de detección de anomalías más prometedoras es la basada en redes neuronales. El concepto consiste en aprovechar las características de aprendizaje de estas redes, para predecir las acciones de los usuarios, dado un número determinado n de acciones previas conocidas. [53]
Las redes neuronales están formadas por numerosos elementos de procesamiento simple denominados unidades que se interactúan entre sí mediante conexiones con peso. El conocimiento de una red neuronal se almacena mediante la indicación de las conexiones entre las unidades y sus pesos. El proceso de aprendizaje se realiza cambiando pesos y aumentando o disminuyendo el número de conexiones.
Figura 3‑20 - Redes neuronales para la detección de anomalías
La red neuronal es entrenada mediante conjuntos de los comandos más significativos. Después de un período de entrenamiento, la red contrasta los comandos obtenidos con el perfil de usuario. Cualquier comando o acción predicha incorrectamente permiten determinar el grado de desviación entre el usuario y el perfil establecido.
En el Departamento de Tecnología Informática y Computación de la Universidad de Alicante se ha hecho un estudio sobre la utilización de redes neuronales en el que se han obtenido extraordinarios resultados [54]. Aplicaron dos métodos en la experimentación: una red de perceptrón multicapa y un mapa auto-organizativo (MAO) [55].
En el estudio se utilizaron como datos de entrada 29 elementos consistentes en elementos de cabeceras de paquetes IP, TCP, UDP, TCMP y datos obtenidos a partir de los contenidos de los paquetes. Luego, en una red local de dos ordenadores, y con la ayuda de la información proporcionada por el escáner de vulnerabilidades Nessus y el IDS Snort, se capturaron un total de 443 paquetes "peligrosos" utilizados en las pruebas. Utilizaron una parte de estos paquetes para entrenar a los sistemas y la otra para probarlos, con unos porcentajes de aciertos de más del 90%.
Las redes neuronales tienen la ventaja de que funcionan bien con datos con ruido. No hacen suposiciones estadísticas sobre la naturaleza de los datos. Son capaces de detectar nuevas formas de ataque no conocidas, sin necesidad de reglas introducidas manualmente. Además, son fáciles de modificar para soportar nuevos conjuntos de usuarios.
Uno de los inconvenientes de estos sistemas está relacionado con la cantidad de datos a utilizar durante el entrenamiento. Las redes neuronales provocarían muchos falsos positivos si los datos son insuficientes, y si son demasiados, el número de datos irrelevantes sería alto, aumentando los falsos negativos. Otro de los puntos en contra de este modelo es que no aporta ninguna explicación sobre las anomalías que identifica, dificultando la posibilidad de corregir las raíces del problema de seguridad en el sistema. Por otra parte, un intruso podría ser capaz de entrenar a la red durante la fase de aprendizaje ("session creep"). Algunos desarrolladores han aportado soluciones híbridas que intentan solventar algunos de estos inconvenientes. [56]
3.2.3.3 Métodos alternativos
Aparte de los métodos de detección mencionados, han ido apareciendo nuevas soluciones, aplicables bien a la detección de usos indebidos, bien a la detección de anomalías.
Con toda seguridad, en un futuro cercano aparecerán más técnicas como las descritas a continuación. Como se comprobará, las posibilidades en el campo de la detección son enormes. Cualquier sistema relacionado con técnicas de aprendizaje, reducción de datos, o toma de decisiones se puede aplicar de algún modo a la detección de intrusiones, bien en la detección de usos indebidos o en la detección de anomalías.
Si bien es cierto que estas técnicas son utilizadas en muchas ocasiones en conjunción con otras más tradicionales, para refinar los procesos de detección, también se encuentran como propuestas independientes.
3.2.3.3.1 Sistema inmune
Esta propuesta consiste en aprovechar las similitudes existentes entre el sistema inmune del organismo y la detección de intrusiones, basadas en la identificación de lo que es propio al sistema y lo ajeno al mismo.
El sistema inmune es capaz de reconocer comportamientos extraños al organismo (antígenos). Los antígenos, en el contexto de un sistema computacional con usuarios y comportamientos individuales, pueden estar relacionados:
- Con comportamientos anómalos del usuario.
- Con ataques conocidos de antemano.
Estas características se pueden utilizar para la detección de anomalías y la de usos indebidos.
Algunos desarrolladores de la Universidad de México (Forrest, Hofmeyr, y Somayagi, entre otros) han aplicado este método a las secuencias de llamadas al sistema, bajo UNIX [57]. Su sistema utiliza pequeñas secuencias de llamadas al sistema, teniendo en cuenta sólo la relación temporal entre las mismas.
El proceso de detección de intrusiones se completa en dos fases. La primera consiste en la creación de un perfil de comportamiento normal. La diferencia de este perfil con respecto a otros comentados en este capítulo es que está centrado en procesos de sistema, no en usuarios. En la segunda fase se utiliza dicho perfil para, a través de desviaciones de comportamiento de sistema, identificar anomalías.
Los resultados obtenidos fueron sorprendentes, permitiendo la detección de anomalías en el comportamiento de varios programas de UNIX históricamente problemáticos. Además, las secuencias de ejecución utilizadas eran bastante reducidas [58].
Por otra parte, en la Universidad de Chile y Concepción se ha propuesto un sistema de detección de intrusiones basado en la Biología, más concretamente en el sistema inmune. [59]
Esta propuesta analiza el comportamiento de usuarios analizando las secuencias de comandos que ejecutan [60][61][62], en un entorno dinámico, en el que el sistema se adapta gradualmente a los cambios de comportamiento de cada usuario. Utilizan dos criterios asociados a las secuencias estudiadas: comandos sucesores, que caracteriza a los usuarios a través de la relación causal de los comandos ejecutados; y secuencia segmentada, mas compleja que la anterior, que busca patrones extensos y tal vez segmentados en las cadenas recogidas. Estas secuencias sirven para crear los perfiles de usuario.
Para el tratamiento y respuesta ante intrusiones, el sistema utiliza una arquitectura distribuida basada en agentes, que se comenta más a fondo en un apartado posterior. Los principales componentes de esta estructura son los denominados AgentesT, nombre derivado de Linfocitos T.
La recopilación de los comandos de consola se realizó a través de un "wrapper" (envoltura) de consola, programada específicamente para esta propuesta, denominada JudaShell (jsh). Esta herramienta no sólo proporciona los servicios usuales de una consola normal y registra los comandos ejecutados, sino que permite el análisis de los datos para facilitar la labor a los agentes, y restringir las operaciones de los usuarios.
Los resultados de la propuesta fueron más que satisfactorios, haciendo este sistema útil tanto en ambientes monousuario como en entornos multiusuario. No obstante, como ya se apuntó, los sistemas susceptibles de ser entrenados corren el riesgo de ser atacados por usuarios que modifican maliciosamente su actitud a largo plazo ("session creep").
En general, el uso de teorías basadas en el sistema inmune para la detección de intrusiones, permite abordar sistemas complejos de forma más simple que muchas otras alternativas, y sin diferencias significativas en los resultados.
No obstante, estas técnicas no deberían utilizarse de forma única, sin el apoyo de algún otro mecanismo de detección complementario. Algunos ataques, tales como los de condición de carrera, enmascaramiento, o violaciones de políticas de sistema no hacen uso de procesos privilegiados, por lo que no son detectados por este enfoque.
3.2.3.3.2 Genética
Los algoritmos genéticos también son de gran utilidad en la detección de intrusiones, como avanzado método de análisis de datos.
Un algoritmo genético es un algoritmo de búsqueda basado en la mecánica de la selección natural y de la genética natural. Combina la supervivencia del más apto entre estructuras de secuencias con un intercambio de información estructurado, aunque aleatorio, para constituir así un algoritmo de búsqueda que tenga algo de las genialidades de las búsquedas humanas [63].
El algoritmo genético es uno de los algoritmos englobados en el conjunto que recibe el nombre de algoritmos evolutivos; los cuales, utilizan las nociones de la selección natural formulada por Darwin para solucionar problemas.
Cada solución será representada a través de una cadena de 0s y de 1s ó cromosomas que se verán entonces sometidos a una imitación de la evolución de las especies: mutaciones y reproducción por combinación. Como se favorece la supervivencia de los más "aptos" (las soluciones más correctas), se provoca la aparición de híbridos cada vez mejores que sus padres. Al despejar los elementos más aptos, se garantiza que las generaciones sucesivas serán cada vez más adaptadas a la resolución del problema.
Para utilizar algoritmos genéticos en la detección de intrusiones, los desarrolladores han definido vectores de hipótesis para los datos de eventos, donde los vectores pueden indicar si ha habido intrusión o no. Entonces, la hipótesis se somete a prueba para determinar si es válida. Con los resultados de la prueba, se desarrolla una versión mejorada (evolucionada) de la hipótesis. Este proceso se repite hasta encontrar una solución.
En el sistema GASSATA, desarrollado por Ludovic Mé, en Francia, aplica el algoritmo genético al problema de la clasificación de eventos mediante el uso de vectores de hipótesis H (uno por cada flujo de eventos relevante) de n dimensiones (donde n representa el número de ataques potenciales). [64]
Los resultados experimentales fueron asombrosos. Se obtuvo una probabilidad de verdaderos positivos del 0.996, siendo de 0.0044 la de falsos positivos. El tiempo necesitado para construir los filtros también fue mínimo. Para un conjunto de 200 ataques, al sistema le llevó 10 minutos y 25 segundos analizar los eventos recopilados durante 30 minutos de intensa actividad de usuario.
En los algoritmos genéticos, los mecanismo de evolución y selección son independientes del problema a resolver: sólo varían la función que descodifica el genotipo en una solución posible y la función que evalúa el ajuste de la solución. Esta técnica es de aplicación general.
Por último, hay que mencionar que el algoritmo genético puede ayudar en la producción de una variedad de objetos, mientras sea posible obtener una calificación que permita expresar la solución. De esta forma, es posible fabricar previsores estadísticos, no a través de cálculos de datos como en la estadística clásica, sino haciendo evolucionar los datos mediante algoritmo genético ("inducción"). El mecanismo de estimulación de los más aptos, permite la aparición del previsor, que reordenará los datos lo mejor posible. Este tipo de construcción de previsor forma parte de las llamadas técnicas de "data mining" (minería de datos), comentada a continuación.
Los previsores producidos pueden tener formas muy diversas, como: bases de reglas, evaluación por puntuación, árboles de decisión e incluso redes neuronales.
3.2.3.3.3 "Data mining" (minería de datos)
Según apuntan algunos, la minería de datos es el sucesor de la estadística clásica. Tanto uno como otra, llevan al mismo fin, construir modelos compactos y comprensibles que relacionen la descripción de una simulación y un resultado relacionado con dicha descripción. A grandes rasgos, la mayor diferencia entre ambos, reside en que las técnicas de minería de datos construyen su modelo de forma automática, mientras que las técnicas estadísticas clásicas deben ser manejadas por un profesional.
La detección de intrusiones que utiliza técnicas de minería de datos es similar a la basada en reglas. Intenta descubrir patrones fiables de características de sistema que puedan definir pautas de comportamiento de sistema y usuario. Estos conjuntos de características de sistema son procesados mediante métodos de inducción por motores de detección que identifican tanto anomalías como usos indebidos.
La minería de datos extrae modelos a partir de grandes cantidades de información. Tiene la peculiaridad de encontrar relaciones ente los datos que serían más difíciles de detectar mediante otros métodos de análisis. Entre los algoritmos disponibles para aplicar la minería de datos sobre datos de auditoría predominan tres: clasificación,análisis de enlace, y análisis de secuencia.
· Clasificación: Asigna los datos a una serie de categorías predefinidas. Los algoritmos de clasificación devuelve clasificadores, tales como árboles de decisión o reglas. En la detección de intrusiones, los clasificadores deciden si los datos de auditoría pertenecen a una categoría normal o anómala.
· Análisis de enlace: Identifica las relaciones y correlaciones entre los campos en el cuerpo de los datos. Un algoritmo de análisis de enlace óptimo reconoce el conjunto de características de sistema más adecuado para revelar intrusiones.
· Análisis de secuencia: Crea patrones de secuencias. Estos algoritmos pueden identificar aquellos eventos que suelen ocurrir juntos, y proporcionar medidas estadísticas de tiempo para mejorar la detección de intrusiones. Estas medidas ayudan en la detección de ataques basados en denegación de servicio.
El número de propuestas sobre de detección de intrusiones basadas en la minería de datos es abundante. Muchas de ellas han sido desarrolladas en la Universidad de Columbia, por Wenke Lee y Salvatore J. Stolfo. Algunos de sus trabajos son "A Data Mining Framework for Building Intrusion Detection Models" [65], "Adaptative Intrusion Detection: a Data Mining Approach"[66], "Mining Audit Data to Build Intrusion Detection Models" [67], o "A Data Mining and CIDF Based Approach for Detecting Novel and Distributed Intrusions" [68].
Una de las ventajas de la minería de datos es que mejoran el rendimiento, la manejabilidad y reducen el tiempo de trabajo. Su capacidad de realizar modelos propios, a partir de algunos tipos de datos (como el consumo de CPU), difíciles de encajar en distribuciones conocidas, les hace idóneos para la detección de intrusiones. Además de su rapidez, también son valorados por su sencillez. Estas técnicas permiten trabajar con importantes cantidades de información sin problemas.
3.2.3.3.4 Detección basada en agentes
Los agentes son aplicaciones de software que realizan funciones de monitorización en máquinas. Funcionan de forma autónoma, es decir, son sólo controlados por el sistema operativo, no por otros procesos. Los agentes están siempre operativos, siendo posible la comunicación y cooperación entre ellos si es necesario.
El grado de complejidad de los agentes es variable. Pueden realizar tareas sencillas como registrar el número de ocasiones en que un usuario entra al sistema, o más complejas como la búsqueda de evidencias de ciertos ataques, de acuerdo con determinados parámetros. Además, tienen la capacidad de responder de forma muy precisa ante posibles intrusiones, por ejemplo, modificando prioridades de procesos.
Dadas sus características, los agentes se pueden utilizar tanto en detección de anomalías como de usos indebidos.
Agentes autónomos
Muchos sistemas de detección de intrusiones utilizan agentes. El sistema denominado Agentes Autónomos para la Detección de Intrusiones (AAFID), propuesto en la Universidad de Purdue, fue uno de los primeros en utilizar estos elementos.
Su arquitectura está organizada de forma jerárquica, en la que existen mecanismos de control y divulgación, tal como se observa en la Figura 3‑21 siguiente. Pueden existir varios agentes por máquina ("host"), y cada uno de ellos envía sus datos a un transmisor-receptor. Estos últimos, coordinan las operaciones realizadas por los agentes y se encargan de su funcionamiento y configuración. Además, realizan funciones de reducción de datos y envían sus resultados al siguiente nivel jerárquico, formado por uno o más monitores.
Los monitores, que pueden estar estructurados en distintos niveles, procesan la información que reciben de los transmisores-receptores. Los monitores pueden obtener datos de toda la red, de forma que pueden detectar ataques multi-máquina ("multi-host"), realizados desde diferentes sistemas. Los monitores son controlados a través de una interfaz de usuario, y utilizan esa información para enviar órdenes a los transmisores-receptores.
Figura 3‑21 - Arquitectura del sistema AAFID
Entre las ventajas de AAFID cabe destacar que es un sistema más robusto que otros mecanismos de detección de intrusiones. Su arquitectura estructurada en niveles, permite la adición o extracción de componentes de forma sencilla. Los agentes pueden ser probados de forma independiente antes de implantarlos en el sistema. Como estos agentes se pueden comunicar entre sí, pueden realizar de forma individual tareas simples, de forma que la tarea conjunta sea más compleja.
No obstante, este sistema también tiene sus desventajas. Si un monitor falla, los datos enviados por los transmisores-receptores conectados a él, dejaran de llegar. Una de las alternativas propuestas más fáciles de imaginar para solventar este problema, es la duplicación de los monitores, análogamente a como se hace con servidores de "backup" en redes. Desgraciadamente, esta situación provoca problemas de consistencia de datos y duplicación de información que requieren técnicas adicionales. Hay problemas, comunes a todos los sistemas de detección de intrusiones distribuidos, asociados al retardo entre la ocurrencia de una incidencia y su llegada al monitor. Otro inconveniente no menos importante, y existente en muchos otros sistemas de detección de intrusiones, es el de contar con una interfaz de usuario demasiado pobre en contenidos. La forma de representar las reglas de sistema, así como las políticas de seguridad es mejorable.
3.2.3.3.5 Lógica difusa
La lógica difusa ("fuzzy logic") es una forma de razonamiento que incorpora criterios múltiples para tomar decisiones y valores múltiples para evaluar posibilidades.
En lógica dicotómica (método de razonamiento, basado en que cada restricción del problema puede ser considerada verdadera o falsa), se espera derivar una solución decidiendo entre sí o no, dependiendo de si cada una de las restricciones o parámetros es verdadero o falso. En cambio, en lógica difusa es posible utilizar escalas de condiciones (restricciones) y matices (flexibilidad) en los valores numéricos. En el intervalo [0..1] puede caber cualquier valor de verdad, sin necesitar ser un número entero. Permite volcar numéricamente expresiones del tipo muy caliente.
Este método se suele utilizar para mejorar y afinar el funcionamiento de otros sistemas. Por ejemplo, en la Universidad de Mississippi, los profesores Susan M. Bridges y Rayford B. Vaughn propusieron un prototipo de sistema de detección de intrusiones inteligente (IIDS) basado en técnicas de "fuzzy data mining" y algoritmos genéticos [69]. Combinaron las capacidades de representación de datos de la lógica difusa, y la capacidad de creación de modelos del "data mining" a partir de grandes cantidades de datos. De esta forma les fue posible utilizar patrones más flexibles y abstractos, más cercanos a la realidad, para la detección de intrusiones.
La lógica difusa permite representar conceptos que pueden pertenecer a varias categorías (categorías solapadas). En la teoría de conjuntos estándar, cada elemento es miembro de una categoría o no lo es. No obstante, la lógica difusa permite la pertenencia parcial a varias categorías.
Detección de Intrusiones Difusa
John E. D., Jukka J., Ourania K y Julie A. D., de la Universidad de Iowa, han extendido el concepto de difuso, desarrollando un detector de intrusiones basado en red bajo el nombre FIRE ("Fuzzy Intrusion Recognition Engine") [70]. Este sistema utiliza una arquitectura basada en agentes, mediante el sistema AAFID, mencionado en el apartado anterior, para distribuir la monitorización. Cada uno de ellos difumina sus entradas de datos. Se comunican con un motor de evaluación difuso, que relaciona los datos recibidos de los agentes mediante reglas difusas para producir diferentes grados de alarmas.
Los sistemas difusos son muy útiles en la detección de escaneo de puertos, y ataques de denegación de servicio, así como la actividad de diversos troyanos o puertas traseras.
Estas son algunas de las ventajas más importantes de los sistemas difusos:
· Pueden obtener y relacionar entradas de datos de orígenes variados.
· Tienen más matices para definir intrusiones difíciles de clasificar por otros sistemas más estrictos.
· Pueden emitir diferentes grados de alarmas.
Los sistemas difusos parecen tener un futuro prometedor en la detección de intrusiones. Sin embargo, es importante tener un alto grado de conocimiento en esta materia para poder afinar correctamente las reglas de detección. Por otra parte, el diseño de los agentes es fundamental en sistemas de este tipo. Su especialización y grado de detalle pueden determinar la identificación de nuevas formas de ataque con éxito.
3.2.3.3.6 Anomalías artificiales
La generación de anomalías artificiales es un modelo propuesto por Wenke Lee, Salvatore J. Stolfo, W. Fan, M. Miller, y P. K. Chan [71]. Consiste en utilizar algoritmos para fabricar anomalías nuevas, a partir de ataques ya conocidos de antemano. De esta forma, se intenta mejorar las capacidades de detección tanto de usos indebidos como de anomalías (detección de intrusiones conocidas y no conocidas). El detector de intrusiones propuesto está basado en red.
Uno de los aspectos que se destacan en el modelo es la necesidad de combinar los dos métodos de detección de intrusiones más comunes: el de clasificaciones, o usos indebidos y el de anomalías.
En circunstancias normales, para la generación de modelos de clasificación, se utiliza información de entrenamiento basada en clases de datos conocidas. La limitación de estos modelos es precisamente, que sólo reconocerán anomalías relacionadas con esas clases. En la detección de anomalías, la limitación es que sólo se utiliza una clase conocida (equivalente a pautas de comportamiento normal; por ejemplo, el número medio de conexiones por sesión), o algunas instancias limitadas de clases conocidas, con el objetivo de reconocer clases no conocidas.
Esta propuesta presenta formas de generar anomalías artificiales, basadas en clases conocidas, para proporcionar un algoritmo de aprendizaje que permita hallar formas de separar las clases conocidas de las no conocidas. Discute formas de generar modelos de detección de anomalías, a partir únicamente de datos normales. Y estudia el proceso de creación de modelos de detección combinada de usos indebidos y anomalías, a partir de datos que contienen clases conocidas.
Los resultados de los experimentos son muy positivos. Demuestran que el detector de anomalías, entrenado con anomalías conocidas y generadas artificialmente, es capaz de detectar más del 77% de todas las clases de intrusiones no conocidas, con más del 50% eficacia. Por otra parte, el detector combinado de usos indebidos y anomalías, es tan eficaz como el detector de usos indebidos simple, identificando intrusiones conocidas, y es capaz de detectar más del 50% de las clases de intrusiones no conocidas, con una eficacia de entre el 75% y el 100% por clase.
3.3 Respuesta
Los resultados obtenidos de la fase de análisis, se utilizan para tomar las decisiones que conducirán a una respuesta. Esta es la tercera y última fase del modelo de un sistema de detección de intrusiones. El conjunto de acciones y mecanismos que se pueden efectuar en esta etapa es amplio. A continuación se describirán los requisitos y tipos de respuesta más comunes.
3.3.1 Primeras consideraciones
Cuando se diseña un plan de respuesta ante posibles intrusiones hay que tener en cuenta el marco de trabajo. Una empresa puede estimar necesario cumplir con los estándares en gestión de seguridad y manejo de incidencias, mientras que un investigador de seguridad que experimenta con una red de laboratorio puede necesitar registrar de forma exhaustiva las actividades de la misma para su investigación. Los productos comerciales deberían ser lo suficientemente versátiles para poder atender las necesidades de los usuarios en este aspecto.
Una de las consideraciones a tener en cuenta al diseñar un mecanismo de respuesta es el entorno operacional en el que se va a utilizar. Un sistema de detección que deba coordinar la información de múltiples agentes, distribuidos a lo largo de una red de producción, no tiene las mismas necesidades de alarma y notificación que un sistema no distribuido, instalado en un ordenador personal.
El elemento monitorizado juega un papel importante en el modelo de respuesta. Una de las razones por las que se proporcionan respuestas activas, como el bloqueo de las conexiones del atacante, se debe a la existencia de sistemas que proporcionan funciones o servicios críticos a los usuarios. Un ejemplo de este caso es el de bancos o comercios electrónicos. Un ataque de denegación de servicio podría ser graves consecuencias en esos casos.
En determinados entornos, se cuenta con procedimientos preestablecidos de obligatorio cumplimiento. Algunas fuerzas militares poseen normas que definen los requisitos y funciones que deben satisfacer los detectores de intrusiones. Si en un determinado momento, el detector no está activo, se indica que dicho sistema no debe trabajar con información clasificada.
Por otra parte, las alarmas y avisos proporcionados por un mecanismo de respuesta deberían presentar suficiente información adicional para indicar las acciones a tomar en cada situación. Algunos productos de seguridad sólo indican el identificador del error mediante un lacónico mensaje, siendo más útil añadir el posible origen del problema y cómo solucionarlo.
3.3.2 Tipos de respuestas
Las respuestas de un sistema de detección de intrusiones pueden ser de dos tipos: pasivas o activas. Las pasivas consisten en la emisión de informes, o el registro de las intrusiones ocurridas. Las activas son las que implican alguna acción en particular, como el bloqueo de conexión, el cierre inmediato de una cuenta, o la prohibición de ejecución de determinados comandos.
Se pueden soportar ambos tipos de respuestas en un sistema de detección. Una no excluye a la otra. Es posible que en determinadas anomalías sólo sea necesario registrar la actividad ocurrida para su posterior examen, mientras que en intrusiones a sistemas críticos haga falta una actuación más activa y urgente. Como se comentó antes, todo depende de las necesidades de cada caso
3.3.2.1 Respuestas activas
Las respuestas activas, como ya se mencionó, afectan al progreso del ataque, pueden ser llevadas a cabo de forma automática por el sistema, o mediante intervención humana.
Estas acciones pueden ser de diversa naturaleza; no obstante, la mayoría se pueden clasificar en estas tres categorías principales: ejecutar acciones contra el intruso, corregir el entorno, y recopilar más información.
3.3.2.1.1 Ejecutar acciones contra el intruso
La más famosa de las respuestas activas, es la de tomar acciones contra el intruso. La forma más directa consiste en identificar el origen de ataque, e impedirle el acceso al sistema. Por ejemplo, desactivando una conexión de red, o bloqueando la máquina comprometida.
Sin embargo, tomar decisiones tan agresivas no es siempre una buena solución. Hay situaciones en las que esto podría causar serios problemas:
· Los ataques recibidos a menudo son realizados, no desde la propia máquina del intruso, sino desde una víctima controlada por aquel. El intruso puede haber utilizado a su víctima mediante algún programa de control remoto, o como resultado de un fallo de seguridad que le permitiera entrar. Si se bloquea o incluso devuelve el ataque en esta situación, se estaría perjudicando a alguien inocente.
· En muchas ocasiones, los atacantes utilizan técnicas de ocultación de su dirección IP ("spoofing"). En este tipo de ataques, las direcciones IP de origen no tienen nada que ver con el atacante. Incluso pueden no existir, hecho beneficioso en casos de ataque de denegación de servicio, en los que el servidor pierde demasiado tiempo esperando la respuesta de direcciones IP que no responden nunca.
· Por otra parte, responder de forma automática a intrusiones puede provocar penalizaciones legales. Si se devuelve el ataque a una entidad inocente, puede efectuar una demanda por daños y perjuicios. Además, en algunas organizaciones, tomar este tipo de decisiones sin la autorización adecuada puede ser razón de despido.
Se pueden realizar acciones contra intrusos menos drásticas. Por ejemplo, terminando la sesión TCP problemática, o bloqueando durante un intervalo de tiempo el origen de las intrusiones, o enviando un correo electrónico al administrador.
Hay que tener en cuenta que ejecutar una respuesta definitiva, de forma automática, es algo delicado. Si en un determinado entorno se bloquean permanentemente las direcciones IP que intentan demasiadas conexiones con el servidor, y un intruso se percata de ello, puede elaborar un ataque que consista en realizar sucesivos intentos de conexión con direcciones falseadas, pertenecientes a los clientes más importantes. De esta forma, el propio detector de intrusiones estaría bloqueando a sus propios clientes, ayudando a un ataque de denegación de servicio.
3.3.2.1.2 Corregir el entorno
Esta opción, como su nombre indica, consiste en efectuar las acciones pertinentes para restaurar el sistema y corregir los posibles problemas de seguridad existentes. En la mayoría de las ocasiones, esta respuesta activa suele ser la acción más acertada.
Aquellos sistemas que cuentan con métodos de de auto-curación ("self-healing"), son capaces de identificar el problema y proporcionar los métodos adecuados para corregirlo.
En muchas ocasiones, este tipo de respuestas puede provocar cambios en el motor de análisis o en los sistemas expertos, generalmente aumentando su sensibilidad e incrementando el nivel de sospecha ante posibles intrusiones.
3.3.2.1.3 Recopilar más información
Recoger información adicional es otra de las respuestas activas. Esta opción es utilizada en ocasiones para cumplir los requisitos de información necesarios para poder tomar acciones legales contra posibles criminales. Normalmente se aplica en sistemas que proporcionan servicios críticos.
Otra de las situaciones en las que se puede dar este tipo de respuesta, es en máquinas o redes que imitan comportamientos y servicios reales, para engañar a los intrusos. Tal es el caso de servidores "decoy" (trampa), "fishbowl" (peceras), o "honeypots" (tarros de miel). Este último tipo, por su creciente rango de características, que lo hacen útil en el ámbito de la detección de intrusiones, es comentado más a fondo en el siguiente capítulo.
La puesta en práctica de un servidor "decoy" fue descrita primera vez a través de un artículo escrito por Bill Cheswick [72]. En él detallaba cómo había creado un servidor "decoy" para redirigir las acciones de un "cracker" holandés que atacaba sus sistemas. El uso de un servidor "decoy" fue comentado por Cliff Stoll en su libro "The Cuckoo's Egg" [73].
Las posibilidades derivadas del uso de servidores "decoy" o "honeypots" son muy amplias, y se explican con mayor detalle en el siguiente capítulo. Por describir algunas de ellas, pueden ser usados para registrar de forma exhaustiva las actividades de un intruso, y aprovechar los resultados para tomar medidas legales. Por otra parte, un servidor trampa puede utilizarse, como ya se ha hecho en alguna empresa, para detectar vulnerabilidades utilizadas por intrusos, aún no publicadas o ni siquiera descubiertas. Otra de las posibilidades que tienen estos sistemas, es la de ayudar a diseñar mejores patrones y reglas de detección, gracias a los registros de actividad obtenidos.
3.3.2.2 Respuestas pasivas
Son aquellas respuestas que consisten en el envío de información al responsable correspondiente, dejando recaer en él la toma de decisiones. En los primeros detectores de intrusiones, todas las respuestas eran pasivas. Aunque la tecnología ha evolucionado mucho desde entonces, las respuestas pasivas siguen existiendo. Y es que, por muy afinados que sean los mecanismos de respuesta automática, hay ocasiones en que un sistema no tiene la responsabilidad suficiente para tomar una decisión.
Las alarmas por pantalla son una de las alarmas más comunes entre los sistemas de detección de intrusiones. Un mensaje en una ventana indica al usuario que se ha cometido una posible intrusión, acompañando a veces el mensaje con información adicional, como la dirección del posible atacante, el protocolo usado, etc. Muchas veces, el contenido de estas alarmas puede ser configurado.
Otra de las posibles formas de recibir respuestas pasivas es a través del correo electrónico o mensajes a un teléfono móvil. La ventaja del segundo caso sobre el primero, es que puede ser recibido en cualquier lugar, cualidad muy apreciada entre administradores. No obstante, un correo electrónico puede contener más información, proporcionando un mensaje más extenso, y menos ambiguo, sobre la incidencia.
Por otra parte, algunos sistemas de detección de intrusiones están integrados con mecanismos de gestión de redes. En estos casos se suele hacer uso de mensajes SNMP (Protocolo Simple de Gestión de Red). La integración con este sistema de comunicación permite utilizar canales ya existentes para el envío de incidencias. No obstante, un uso excesivo por parte de detectores de intrusiones de estos canales, podría perjudicar a otros sistemas que también hicieran uso de ellos.
3.3.3 Observaciones sobre las respuestas
Para que la fase de respuesta de un detector de intrusiones tenga relativo éxito, hay que tener ciertos aspectos en cuenta. Desde que se detecta una actividad sospechosa, hasta que se comunica a la entidad correspondiente, se producen una serie de pasos en los que hay que salvar diversos obstáculos. Mantener cierta seguridad en la comunicación de las respuestas, configurar adecuadamente el detector de intrusiones para minimizar los falsos positivos, o proporcionar métodos de almacenamiento apropiados para las notificaciones, son algunos de los que se describen a continuación.
3.3.3.1 Aspectos de seguridad
Los propios sistemas de respuesta pueden ser importantes objetivos de ataque. El bloqueo de las respuestas de un detector de intrusiones, dejaría a este sistema mudo, anulando toda su eficacia. Por ello, los productos desarrollados suelen dedicar especial atención a este apartado.
3.3.3.1.1 Comunicación oculta
Una de las cuestiones que los detectores de intrusiones tienen presente, es la de no ser reconocidos por atacantes. Cuando un sistema está siendo comprometido, no conviene que el intruso se percate de que está siendo monitorizado. Por esta razón, se utilizan técnicas que permitan al detector de intrusiones registrar todo lo sucedido y comunicar las incidencias a los responsables, todo ello sin ser interceptado.
En la mayoría de las ocasiones se suele utilizar canales de comunicación cifrados. De esta forma, el intruso no puede detectar ni modificar el contenido de las comunicaciones.
3.3.3.1.2 Redundancia
Otra de las soluciones recomendadas, es el uso de la redundancia en las comunicaciones. Es decir, en situaciones de alarma críticas, conviene utilizar más de una vía de comunicación para transmitir la misma notificación. Se puede enviar mensaje por un canal cifrado y otra a través de mensajes de gestión de red. Así, se reducen las probabilidades de que los mensajes sean bloqueados.
3.3.3.1.3 Protección de registros
Una vez comunicadas las alarmas hay que almacenarlas de forma segura, protegiéndolas ante alteraciones o eliminaciones. Esto es especialmente importante cuando se pretende utilizar el material obtenido para asuntos legales. También aquí se utiliza redundancia, en los casos más importantes.
Una de las soluciones practicadas es el almacenamiento de los registros en medios de una sola escritura, como un CD-ROM o incluso una impresora de papel continuo.
3.3.3.2 Falsas alarmas
Uno de los problemas asociados a los mecanismos de respuesta de los sistemas de detección de intrusiones es el de las falsas alarmas. Son de dos tipos: falsos positivos, que indican posibles intrusiones cuando en realidad no los hay; y falsos negativos, que no notifican intrusiones cuando realmente han tenido lugar.
Los falsos negativos representan un problema, en el sentido de que al sistema se le escapan muchas actividades sospechosas. La solución pasa por mejorar la sensibilidad del detector, afinando la configuración o desarrollando mejores técnicas de detección.
Los falsos positivos pueden ser también peligrosos si se producen con demasiada frecuencia. Pueden hacer que el responsable de seguridad acabe ignorándolos, o no distinguiendo entre ellos las verdaderas alarmas. En el peor de los casos, pueden llegar a colapsar al sistema. Una de las posibles soluciones a esta situación consiste en disminuir la sensibilidad del motor de detección de anomalías, adaptando los resultados al comportamiento normal del sistema.
3.3.3.3 Almacenamiento de registros
Casi todos los detectores de intrusiones comerciales tienen métodos especiales para conservar los registros generados a través de sus mecanismos de respuesta pasiva. Buena parte de ellos contempla la posibilidad de almacenarlos en bases de datos. Esto simplifica en gran medida su análisis ulterior. Además, permite a los responsables de seguridad entregar informes detallados de la actividad del sistema a los encargados de la gestión ejecutiva.
Conviene que los registros de los sistemas de detección de intrusiones sean almacenados de forma similar a los registros de sistema, y en medios seguros, como ya se comentó en apartados anteriores. Uno de los motivos por los que se hace esto, es para ayudar en operaciones legales e investigaciones forenses.
3.3.4 Adopción de políticas de respuesta
La correcta gestión de la seguridad de un sistema de detección de intrusiones conlleva el cumplimiento de una serie de procedimientos, que definan las acciones a tomar en caso de problemas. Estos procedimientos deben estar incluidos en las políticas de seguridad de la organización. Las actividades contempladas por las políticas de seguridad, en caso de intrusiones o violaciones de seguridad, están dividas en cuatro categorías: intermedia o crítica, oportuna, largo plazo - local, y a largo plazo - global [23].
3.3.4.1 Intermedia o crítica
Estas son algunas de las acciones a realizar justo después de percibir un ataque o intrusión:
· Procedimientos de manejo de incidencias.
· Contención y control de daños.
· Notificación a las autoridades legales y otras organizaciones.
· Restaurar el servicio en los sistemas afectados.
3.3.4.2 Oportuna
A continuación se indican las acciones a tomar después de un ataque o violación de seguridad. El tiempo en que se llevan a cabo puede variar entre unas horas y varios días, dependiendo de la organización y el grado de importancia:
· Investigar manualmente patrones inusuales de uso del sistema.
· Investigar y aislar las causas del problema.
· Corregir estos problemas cuando sea posible, aplicando parches o corrigiendo la configuración del sistema.
· Notificar los detalles del incidente a los responsables adecuados.
· Mejorar las firmas o patrones de detección del sistema de detección de intrusiones.
· Tomar acciones legales contra el intruso.
3.3.4.3 Largo plazo - local
Las acciones de largo plazo local son menos críticas que las pertenecientes a las dos categorías anteriores. No obstante, no deben dejar de realizarse, ya que desempeñan un papel imprescindible en la seguridad del sistema. Se llevan a cabo a de forma periódica, durante la administración de un sistema.
Actividades como las descritas a continuación, permiten la prevención de posibles ataques, y mejoran de forma constante la configuración de los elementos de seguridad del sistema:
· Compilar estadísticas y realizar análisis de las tendencias de uso y comportamiento.
· Seguir la pista de patrones de forma continua.
3.3.4.4 Largo plazo - global
Estas acciones corresponden a actividades no críticas, pero que no deben ser ignoradas. El impacto de estas acciones no está limitado a la organización. Algunos aspectos de la seguridad de sistema no pueden ser resueltos de forma local. Acudir a otras entidades puede hacer que la organización sea partícipe de una solución más completa. Algunas de estas acciones son:
· Notificar a los vendedores de los posibles problemas de seguridad encontrados en sus productos.
· Acudir a entidades legisladoras y al gobierno para solicitar mejores medidas legales contra violaciones de seguridad de sistemas.
· Enviar estadísticas sobre incidentes de seguridad a autoridades legales u otras organizaciones que mantengan este tipo de estadísticas.
3.4 Referencias
[3] Sun Microsystems, Inc. System Administration Guide: Security Services. BSM (Overview), 2002. Santa Clara, CA.
[4] Josué Kuri, Gonzalo Navarro, Ludovic Mé, Laurent Heye. A Pattern Matching Based Filter for Audit Reduction and Fast Detection of Potential Intrusions. Springer-Verlag Berlin Heidelberg, 2000.
[8] World Wide Web Consortium. Logging Control In W3C httpd - The Common Logfile Format. [en línea]. Julio 1995 [consultado en febrero 2003]. Disponible en <http://www.w3.org/Daemon/User/Config/Logging.html>.
[9] World Wide Web Consortium. HTTP - Hypertext Transfer Protocol. [en línea]. Julio 1995 [consultado en febrero 2003]. Disponible en <http://www.w3.org/Protocols/>.
[10] RENT-A-GURU. HTTP-ANALYZE - A Log Analyzer for web servers. [en línea]. 27 de septiembre, 2002 [consultado en febrero 2003]. Disponible en <http://www.http-analyze.org/>.
[11] Sanctum Inc. Appshield. [en línea]. Fecha no disponible [consultado en abril 2003]. Disponible en <http://www.sanctuminc.com>.
[13] González Gómez, Diego. Cables UTP de sólo recepción. [en línea]. Junio, 2003 [consultado en junio 2003]. Disponible en <http://www.dgonzalez.net/pub>.
[14] The Moschovitis Group. History of the Internet: Birth of TCP/IP Networking Protocol. [en línea]. 1999 [consultado en febrero 2003]. Extractos del Capítulo 4 - Because It's there: 1979-1984. Disponible en <http://www.historyoftheinternet.com/chap4.html>.
[15] Stevens, W. R. TCP/IP Illustrated, Volume 1. Addison-Wesley, Reading, Massachusetts, 1994.
[16] Kirkpatrick S., Stahl M., Recker M., Internet Numbers. Internet Engineering Task Force. [en línea]. Julio, 1990 [consultado en febrero, 2003]. Request for Comments: 1166. [182 pp.] Disponible desde Internet <http://www.ietf.org/rfc/rfc1166.txt >
[17] Postel, J., Internet Protocol. Internet Engineering Task Force. [en línea]. Septiembre, 1981 [consultado en febrero, 2003]. Request for Comments: 791. [45 pp.] Disponible desde Internet: <http://www.ietf.org/rfc/rfc791.txt >. También disponible en castellano en <http://www.rfc-es.org/rfc/rfc0791-es.txt>.
[18] Postel, J., Transmission Control Protocol. Internet Engineering Task Force, [en línea]. Septiembre, 1981 [consultado en febrero, 2003]. Request for Comments: 793. [85 pp.] Disponible desde Internet: <http://www.ietf.org/rfc/rfc793.txt>. También disponible en castellano en <http://www.rfc-es.org/rfc/rfc0793-es.txt>.
[21] Driver Development for SCO Systems. Streams Driver Overview. The Santa Cruz Operation, Santa Cruz, CA, 1999.
[22] Sunstrom, Peter. fwlogsum - Firewall Report Summariser. [en línea]. Actualizado el 1 de marzo 2003 [consultado en Marzo de 2003] Actualizado contínuamente. Disponible desde Internet en <http://www.ginini.com.au/tools/fw1/>
[23] Bace, Rebecca. Intrusion Detection. Macmillan Technical Publishing, 2000.
[24] Lunt, T., A. Tamaru, and F. Gilham. IDES: A Progress Report. Proceedings of the Sixth Annual Computer Security Applications Conference, Tucson, AZ, December 1990.
[25] Jackson, P. Introduction to Expert Systems. International Computer Science Series. Addison Wesley, 1986.
[26] Roesch, Marty et al. Snort.org. [en línea]. Actualizado semanalmente [consultado en marzo de 2003]. Disponible en <http://www.snort.org>.
[27] Paxson, Vern. Bro: A System for Detecting Network Intruders in Real-Time. Lawrence Berkeley National Laboratory, Berkeley, CA and AT&T Center for Internet Research at ICSI, Berkeley, CA. [en línea]. 14 de diciembre de 1999 [consultado en marzo de 2003]. Disponible desde Internet en <http://www.icir.org/vern/bro-info.html>
[30] Ilgun, Koral. USTAT: A Real-Time Intrusion Detection System for UNIX. Master thesis, University of California, Santa Barbara, CA, November 1992.
[31] Kumar, S. and E.H. Spafford. A Pattern Matching Model for Misuse Intrusion Detection. Proceedings of the Seventeenth National Computer Security Conference, Baltimore, MD, October 1994.
[34] NFR. Network Flight Recorder. [en línea]. Fecha no disponible [consultado en marzo, 2003]. Disponible desde Internet <http://www.nfr.net>.
[40] Smaha, Stephen E. Haystack: An Intrusion Detection System. Proceedings of the IEEE Fourth Aerospace Computer Security Applications Conference, Orlando, FL, December 1988.
[43] Hoagland, J., S. Staniford. Silicon Defense. SPICE / SPADE. [en línea]. Actualizado con frecuencia [consultado en marzo, 2003]. Disponible desde Internet en <http://www.silicondefense.com/software/spice/>.
[45] Mahoney, Matthew, P. K. Chan. PHAD: Packet Header Anomaly Detection for Identifying Hostile Network Traffic. Florida Tech. technical report 2001-04. Disponible en <http://cs.fit.edu/~tr/ >.
[46] Mahoney, Matthew, P. K. Chan. Learning Nonstationary Models of Normal Network Traffic for Detecting Novel Attacks. Edmonton, Alberta: Proc. SIGKDD, 2002, 376-385.
[47] Mahoney, Matthew, P. K. Chan. Learning Models of Network Traffic for Detecting Novel Attacks. Florida Tech. technical report 2002-08. Disponible en <http://cs.fit.edu/~tr/>
[48] Mahoney, Matthew. Network Traffic Anomaly Detection Based on Packet Bytes. Florida Institute of Technology. Melbourne, Florida, 2003.
[49] Lankewicz, Linda and M. Benard. Real-Time Anomaly Detection Using a Nonparametric Pattern Recognition Approach. Proceedings of the Seventh Computer Security Applications Conference, San Antonio, TX, December 1991.
[50] Liepins, G. E. and H. S. Vaccaro. Intrusion Detection: Its Role and Validation. Computers and Security, v 11, Oxford, UK: Elsevier Science Publishers, Ltd, 1992: 347 - 35 5.
[67] Lee, Wenke, Salvatore J. Stolfo, Kui W. Mok. Mining Audit Data to Build Intrusion Detection Models. Computer Science Department, Columbia University, August 1998.
[68] Lee, Wenke, Rahul A. Nimbalkar, Kam K. Yee, Sunil B. Patil, Pragneshkumar H. Desai, Thuan T. Tran, and Salvatore J. Stolfo. A Data Mining and CIDF Based Approach for Detecting Novel and Distributed Intrusions. Computer Science Department, North Carolina State University. Computer Science Department, Columbia University
[71] Lee, Wenke, Wei Fan, Mattew Miller, Salvatore J. Stolfo, Philip K. Chan. Using Anomalies to Detect Unknown and Known Network Intrusions. College of Computing. Georgia Tech. IBM T.J. Watson Research. Columbia University. Computer Science, Florida Tech. November 2001.
[73] Stoll, Clifford. The Cuckoo's Egg: Tracking a Spy Through the Maze of Computer Espionage. New York, NY: Doubleday, 1989.
(1) La clase C2, descrita en el Libro Naranja, pertenece a las clases de "Protección Discrecional" (tipo C). Define una serie de capacidades de auditoría referentes al control de acceso y hace responsables a los usuarios de sus acciones.
(2) El "National Center for Supercomputing Alliances" (NCSA) fue el responsable de la creación del primer navegador extensamente conocido.
(3) libpcap es un interfaz independiente del sistema, para la captura de paquetes de nivel de usuario, escrito en el Lawrence Berkeley National Laboratory.
(4) tcpdump es una herramienta, basada en libpcap, que permite la captura y filtrado del tráfico (mediante expresiones booleanas) que pasa por un dispositivo de red, mostrando las cabeceras de los paquetes, o escribiendo el contenido de los campos de datos en un fichero de registro indicado.
(5) El nombre IDIOT fue utilizado como un chiste por su autor. Significa "Intrusion Detection In Our Time" (Detección de Intrusiones en nuestro tiempo); refiriéndose a los retrasos que muchos desarrolladores de detección de intrusiones deben soportar para poder implementar sus desarrollos en sistemas de producción..